「Metashape」のクラスタ構成での処理速度測定と傾向検証 (後編)
先日公開を致しました前編の記事では、同じ仕様のマシン4台のクラスタ構成での
「Metashape」の処理速度測定の実施とその傾向を検証しました。
その結果を元に、こちらの後編では「CPUのコア数優先」処理の傾向を検証します。

※本ページの記事は「後編」となります。前編記事はこちら
検証環境について
計測は、前回同様の下記クラスタノードをベースとした構成に、CPUのコア数を増やした仕様を1台、CPUノードとして追加し、実施しました。
クラスタノード
| CPU | Intel Core i9 9900K (3.60GHz/TB5.0GHz, 8C/16T) |
| メモリ | 40GB |
| SSD | 1TB S-ATA |
| GPU | Geforce RTX 2080Ti × 1 |
| LAN | Onboard(1GbE) |
| OS | Microsoft Windows 10 Professional 64bit |
| Metashape | Ver 1.5.2.7838 |
追加したCPUノードは以下のスペックとなります。
CPUのコア数は2CPU構成で16コアとなり、2CPUのXeon仕様としては最上位クラスの定格クロックとTBクロックの構成となります。
CPUノード
| CPU | Xeon Gold 6144 (3.50GHz/TB4.20GHz, 8C/16T) × 2 (合計16コア) |
| メモリ | 768GB |
| OS | Microsoft Windows 10 Professional 64bit |
処理内容について
今回行った処理はオルソ画像処理の一連のバッチ処理となります。
この処理においては、前編で使用したDollのサンプルデータですと少し負荷が低めのため計測結果の差が判別しづらかったため、以下のようなデータを弊社で用意し、使用しました。
■ ドローンからのキャベツ畑の撮影画像:1枚あたりおよそ20Mpix(2000万画素)の画像を183枚

処理内容は前回同様、①MatchPhotos ②AlignCameras ③BuildDepthMaps ④BuildDenseCloud ⑤BuildModel ⑥BuildUV ⑦BuildTexture を実施します。
計測方法としては、上記CPUノード構成のマシンをCPUのみを使用する設定でノードとして使用し、ノード処理の優先順位をHighestに設定しております。これで⑤BuildModel~⑦BuildTexture でのCPU処理はこちらのノードで計算されることになります。ただし、他の処理においてもCPUでも計算する場合にはこのノードに処理が割り振られておりますので、個別の部分では多少の差異がある点はご注意ください。
Metshape側の処理は以下のパラメーターでの実施となります。
Aligen Photos : Highest
Build Dense Cloud : Ultra High
Build Mesh : High field&High
Build Texture : Orthophoto
(今回はBuild Meshの処理がHighクオリティとなります。理由に関しましては後述します)
処理結果について
まずは①MatchPhotos~⑦BuildTexture までの一通りのトータル処理時間を計算した結果です。
| クラスタ 1台 (RTX 2080Ti × 1) | 4時間33分01秒 |
| クラスタ 2台 (RTX 2080Ti × 2) | 3時間45分45秒 |
| クラスタ 3台 (RTX 2080Ti × 3) | 3時間33分33秒 |
| クラスタ 4台 (RTX 2080Ti × 4) | 3時間31分35秒 |
| クラスタ 4台 (RTX 2080Ti × 4) + CPU Node |
3時間17分09秒 |
| 比較用単体システム (RTX 2080Ti × 2) | 4時間16分33秒 |
※比較用単体システムのスペックについては前編をご参照ください
次に前編と同様に各フェーズについて検証します。
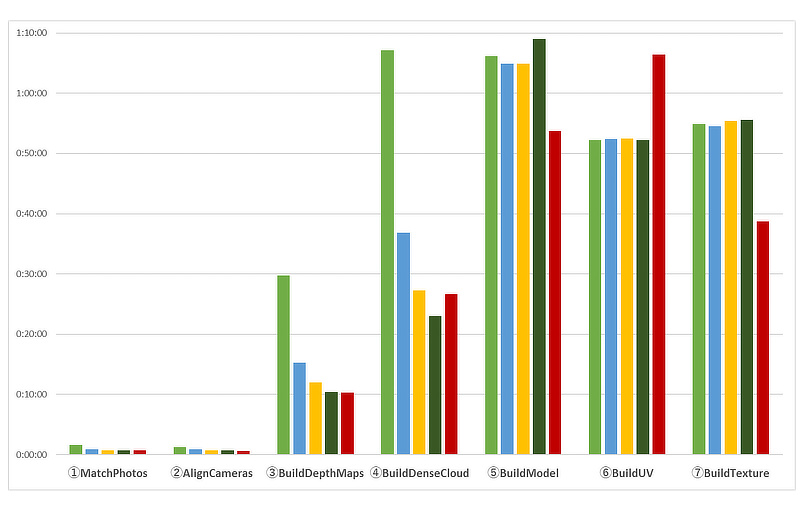
(Y軸=経過時間 : グラフが長いほど処理に時間がかかっている)
#比較用単体システムについては前回同様上記のグラフには載せていません。
予想通り、⑤BuildModel~⑦BuildTextureの部分でCPUノードを追加した場合に大きな変化が見られました。同一ノードのみで実施の場合は前回同様に処理時間は横並びですが、CPUノードに処理をさせた事で差が発生しました。⑤BuildModelと⑦BuildTextureに関しては処理時間が短くなり、逆に⑥BuildUVに関しては長くなっています。
ここで改めて今回のクラスタノードとCPUノードのCPUを比較します。
クラスタノード
| CPU | Intel Core i9 9900K(3.60GHz/TB5.0GHz 8C/16T) ×1 |
CPUノード
| CPU | Xeon Gold 6144 (3.50GHz/TB4.20GHz 8C/16T) × 2 (合計16コア) |
クラスタノード側の方が単独コアの動作速度は速く、CPUノード側の方がコア数が多いといった関係になります。ここから、⑤BuildModel 及び ⑦BuildTexture時間はコア数が有効に働く処理であり、⑥ BuildUVは単独コアの動作速度が重要であるということが推測されます。
また、④BuildDenseCloudの処理時間については、4ノード(クラスタ4台)の結果よりも時間がかかっています。これはGPU処理よりも処理速度が遅いCPUにCPUノードが増えた分だけ処理が分散されてしまい、GPU搭載のクラスタノードは処理が終わっていても、CPU側の処理が終わらず、その処理が終了するのを待ってしまっていた結果と推測されます。実際にはこの処理はログ上では複数の処理に分割され (今回の検証においては106~108 程度)、処理が終わったら次の処理…と渡されていくため、分割された最後の処理が終わるタイミングによっては逆に処理時間は速くなる可能性も考えられます。
なお今回のクラスタノードは同一のCPU/GPU構成ですが、異なるCPUやGPUでの構築をされた場合、速度の遅いCPUやGPUなどがこの処理でボトルネックになる可能性があるということが考えられます。
最後に、「処理内容について」の項目で挙げました、Build Meshの処理をUltra Highで実施しなかった理由については『実施できなかったため』となります。1クラスタあたり40GBのメモリでは今回のデータを処理するのには足りず、処理が進みませんでした。
潤沢にメモリをもっているCPUノード構成 (768GB)の場合はUltra Highでも処理が可能でしたので、Build Meshに関してはノード1台に処理が集中してしまう関係上、その1台に十分なメモリが必要であると推測されます。
まとめ
以上、クラスタを利用したMetashapeの処理速度の検証結果となります。
前編・後編を通してのここまでのデータを元に検討しますと、④BuildDenseCloud処理まではクラスタ構成が有利ですが、それ以降の処理についてはあまり効果的ではないと言えそうです。
また、上記でも触れております通り、Build Meshなどの処理は結局の所、 1台のCPUで処理をする必要があり、その1台に十分なメモリ容量も必要となってきます。クラスタ構成を検討する場合でも、全体の処理として考えた場合に、メモリが足りない事により必要としている処理ができないという可能性がございますので、少なくとも1台は十分なメモリを積んだPCを用意していただくのがよろしいかと思います。
単独クロックの速いCPUを選択しても、搭載できるメモリ容量には上限がありますので、メモリ搭載量の面で見れば、Xeonシステムのほうが有利となります。そのため、単純に単独クロックが速いCPUがお勧めとも言い切れないところがあります。
※今回検証に使用したCPU (Core i9 9900K)は64GBまでのメモリに対応となります (2019年4月時点。将来のRevでは128GBに対応が予定されています)。
現状でMetashapeクラスタ構成を検討する場合、通常は個別で利用しているMetashapeを、大規模な処理が必要な場合に一時的にクラスタとして利用する使い方や、④BuildDenseCloud処理までの作業を行わせるサーバーファームとしての運用等が考えられます。
なお、今回の検証では速度計測をメインにおいておりましたので、すべて1ジョブのみで実施をしておりましたが、当然複数のジョブを実行することも可能です。この場合、処理がBuild Meshに入った時点で、計算している1台のマシン以外がフリーになった場合には次のジョブが走り始めますので、複数のジョブを投げて短時間で処理をさせるという用途でもクラスタ構成は有効であると思われます。
| ■ 2019年7月11日追記 : こちらの検証に利用したクラスタノードPCを事例として公開しました |




