主要なAIモデルにおける RTX シリーズ GPUのパフォーマンス比較検証

弊社で提供しているオーダーメイドPC製作サービス TEGSYSでは、お客さまのご要望に合わせ、最適なスペックのPCをご提案しております。
本記事では、弊社で取り扱いのある現行GPUについて、TensorFlow、PyTorch等主要なAI、ディープラーニング環境での性能や優位性を比較検証しました。
GPUはRTX 2080 Ti、RTX 4090、RTX A6000、RTX 6000 Adaの4種類で比較しています。
お客様の要件にマッチしたマシンを検討するための参考情報としてご覧ください。
検証方法
本記事では、学習モデルとGPU、コンピュータ本体、パフォーマンスの評価項目を以下のように定めて検証を行いました。
比較するモデルの種類
パフォーマンステストに使用したモデルの概要は下記の通りです。
| ResNet-50 | |
| 50層の畳み込みニューラルネットワーク、画像認識モデルで主に利用される | |
| タイプ:畳み込みニューラルネットワーク (CNN) | タスク:画像分類 |
| BERT | |
| 自然言語の文脈や関係性を処理するために主に利用される | |
| タイプ:トランスベースのモデル | タスク:自然言語処理 (NLP) |
| U-Net | |
| 医療画像解析で一般的に使用されており、画像内の観察対象の位置や範囲の抽出に利用されている | |
| タイプ:畳み込みニューラルネットワーク (CNN) | タスク:セマンティック・セグメンテーション |
| GPT-2 | |
| 大規模言語モデルで、テキスト生成、翻訳、質問応答など、さまざまな自然言語処理タスクを実行できる | |
| タイプ:トランスベースのモデル | タスク:テキストと自然言語処理 (NLP) |
比較するGPUの仕様
比較に使用したGPUとスペックは下記のとおりです。
※RTX2080Tiは旧世代製品の比較参考のため掲載しています
| Attributes | RTX 2080Ti | RTX 4090 | RTX A6000 | RTX 6000 Ada |
| GPU architecture | NVIDIA GeForce RTX 2080 | NVIDIA GeForce RTX 4090 | NVIDIA GeForce RTX A6000 | NVIDIA GeForce RTX 6000 Ada |
| CUDA core | 4352 | 16384 | 10752 | 18176 |
| Tensor core | 544 | 512 | 336 | 568 |
| RT core | 68 | 128 | 84 | 142 |
| memory size | 12 GB GDDR6 | 24 GB GDDR6X | 48 GB GDDR6 | 48 GB GDDR6 |
| memory bandwidth | Up to 616 GB/s | Up to 1008GB/s | Up to 768GB/s | Up to 960GB/s |
| Maximum power consumption | 250W | 450W | 300W | 300W |
コンピュータ仕様
GPU以外のハードウェア仕様は、以下の条件に揃えてパフォーマンスを測定しました。
| Chipset | Intel W790 |
| CPU | Intel Xeon w7-2465X |
| RAM | 合計64GB (DDR5-4800 ECC Registered 16GB x4) |
| Storage | 1.92TB SSD S-ATA |
パフォーマンスの評価項目
パフォーマンスは、各GPUモデルでBatch Size を”10″、”1000″ にそれぞれ設定した場合の推論時間 “Inference Time” で評価しました。
| Batch Size | モデルを通過する1回のフォワードパスで一緒に処理されるインスタンスの数。 バッチサイズを大きくすると、GPUの使用率が向上することがよくあります。 |
| Inference Time | モデルが与えられたバッチに対して推論を実行するのにかかる時間。 値が小さいほど高いパフォーマンスを発揮したことを示します。 |
測定結果
Batch Sizeごとの推論時間グラフ
それぞれの推論時間をグラフ化しました。
クリックすると大きいサイズでグラフをご覧いただけます。
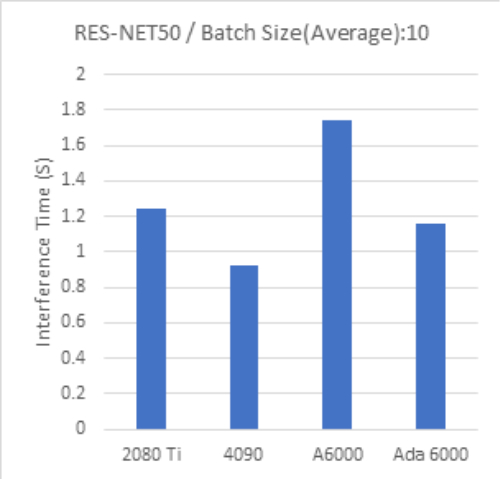
| RESNET-50 Batch Size:10 |
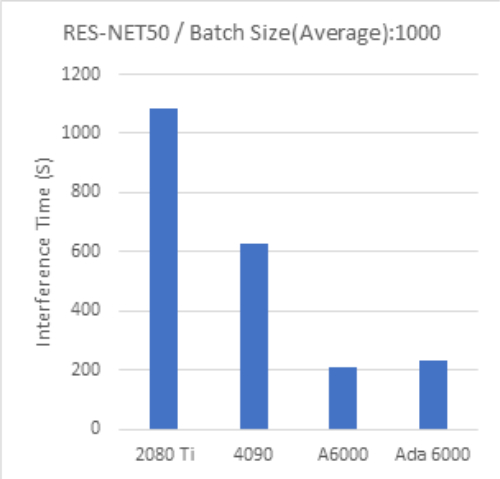
RESNET-50 Batch Size:1000 |
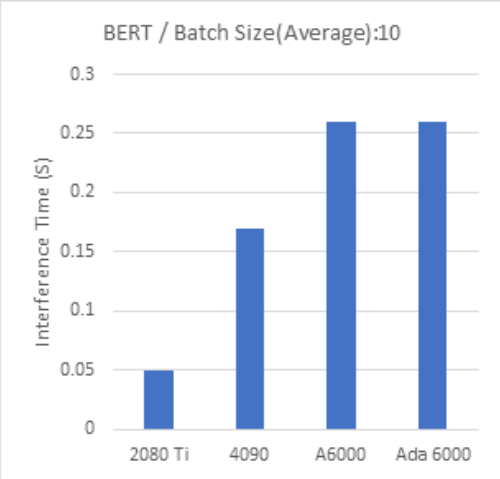
BERT Batch Size:10 |
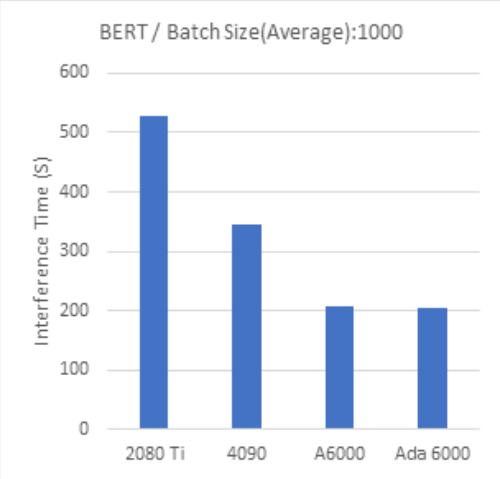
BERT Batch Size:1000 |
 |
 |
 |
 |
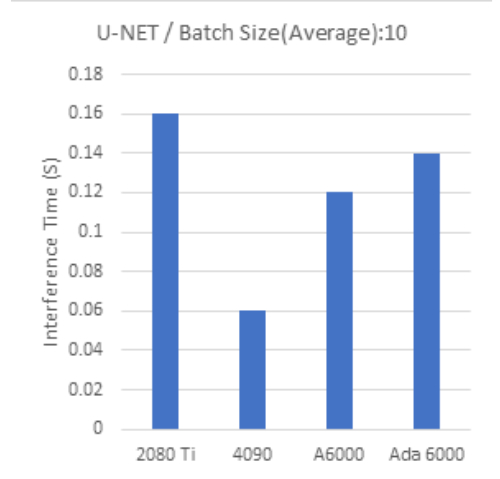
| U-NET Batch Size:10 |
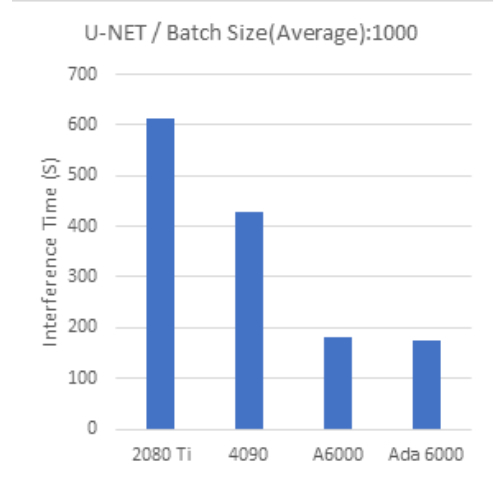
U-NET Batch Size:1000 |
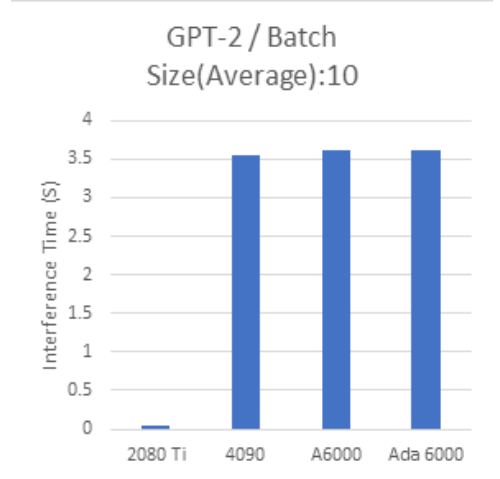
GPT-2 Batch Size:10 |
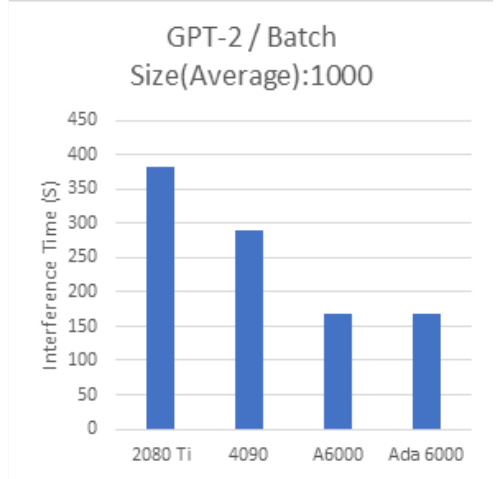
GPT-2 Batch Size:1000 |
 |
 |
 |
 |
測定結果まとめ
Batch Size 1000 では、全般的にビデオメモリ容量の大きなモデルほどより高いパフォーマンスとなる傾向が見られます。
一方で Batch Size 10 で行った今回のテストでは、最新世代のGPUの計算時間が長い傾向が見られ、GPUの性能を引き出せていないと思われる部分があります。
また、小さいバッチサイズでは推論に利用したモデル間でも結果にばらつきが見られます。
特にGPT-2ではRTX2080Tiとそれ以外のGPUによる結果の差が非常に大きく、RTX2080Tiのパフォーマンスも正常な結果ではない可能性が考えられます。
小さなバッチサイズで処理をしても問題ない、小規模なデータを扱う際は、相対的に安価なRTX4090を使用することでコストパフォーマンスを高めることが期待できます。
一方、より大きなバッチサイズを必要とする大規模なモデルで大量のデータを扱う場合は、ビデオメモリ容量の大きなGPUを利用することが効果的と考えられます。
今回の検証では、純粋に各GPUの性能の比較を意図し、GPU処理を実行するためのライブラリやアプリケーションのバージョンは固定したまま、GPUのみを差し換えて検証を行いました。
上述のRTX A6000とRTX 6000 Adaの結果に大きな差が見られない理由は、ソフトウェアの構成が結果としてGPUの個々のモデルに対して最適ではないことに起因している可能性があります。
(なお、本検証はCUDA Toolkit 12.3、cuDNN 8.9.7をインストールした環境にて行っています)
GPUによって最適な学習パラメータが異なること、または、学習したい内容によって最適なGPUが変わることが考えられますので、本記事の内容を踏まえ、バッチサイズの調整などによる影響を分析した記事を続編として公開する予定です。
おわりに
弊社では、AI・ディープラーニング用途向けのPCやワークステーション以外でも、お客さま個別のご要望に合わせ、最適なスペックのPCをご提案しております。
これまでのご提案実績や検証結果等のノウハウをもとにベストな提案を目指しておりますので、PC導入はお気軽にご相談ください。
|
DeepLearning環境における最適なGPU選びのご相談はお気軽に! 研究用・産業用PCの製作・販売サービス TEGSYS – テグシス
|





