- 事例No.PC-TW2M253280
-

大容量VRAM搭載LLMローカル検証用ワークステーション
用途:ローカル環境でのLLM検証 (Ollama)参考価格:5127430円お客さまからのご相談内容
大規模言語モデル(LLM)のローカル検証を目的にした、高性能PCを導入したい。
VRAM容量は不問、可能な限り多くの高性能GPUを搭載した構成を希望する。
予算は250万〜500万円程度で、Ollamaの利用を想定。
GPUドライバー、CUDA ToolkitおよびcuDNNのプリインストールも依頼したい。
環境は、200V電源の使用が可能。テガラからのご提案
GPUの選定について
今回の用途では、GPU性能とVRAM容量の両立が重要です。
LLMによっては140GB程度のVRAMが必要となることもあるため、NVIDIA RTX PRO 6000 Max-Q(96GB)を2枚搭載する構成をご提案しました。
さらに、3枚目のRTX PRO 6000 Max-Qの増設にも対応できるよう、空きPCIeスロットを確保した設計です。テグシスでは LLM における GPU 性能差をまとめた技術記事を公開しています。
前編では RTX 5090 / RTX 4090 / RTX 5000 Ada の実測比較を、続編では RTX PRO 6000 Max-Q を加えた検証 をご紹介しています。
詳細な検証結果は、下記をご覧ください。

メモリ構成と拡張性
LLMの推論では、VRAMを十分に確保することが前提となり、あわせてシステムメモリも同程度以上の大容量が求められます。
本構成では、256GB (64GB×4枚) のメモリを実装し、空きスロットには同容量 (64GB) のモジュールを増設可能です。将来的に3枚目のGPUを増設する場合、VRAMの総量は 96GB × 3 = 288GB となります。
その際には、空きスロットを活用してメモリを増設することで、適切なシステムメモリを無理なく満たせます。
これにより、GPU増設後もボトルネックを避けて、安定したデータ処理を実現できます。ソフトウェアの事前環境構築
GPUドライバー、CUDA Toolkit、cuDNNを適切なバージョンでプリインストールし、即時利用可能な環境で納品します。
PyTorchなどのフレームワークは、お客様によるセットアップを予定していますが、当社でも導入実績があり、必要に応じてご相談も承ります。このような分野で活躍されている方へ
- 人工知能
- 自然言語処理
- 機械学習
- 計算機科学
- 情報システム
テガラのオーダーメイドPC製作サービスは、導入時の用途に加え、将来的な研究規模の拡大を見据えたシステムの拡張にも対応しています。
各種ソフトウェア要件に応じた構成のご提案はもちろん、研究環境全体の構築に関するご相談も承っています。
お客様のニーズに合わせて最適なソリューションをご提供しますので、どうぞお気軽にお問い合わせください。







通常24時間以内に担当者からご連絡いたします
主な仕様
CPU Intel Xeon W3-2525 3.50GHz (TB3.0時 最大4.5GHz) 8C/16T メモリ 合計256GB DDR5 5600 REG ECC 64GB x 4 ストレージ 1TB SSD S-ATA ビデオ NVIDIA RTX PRO6000 Max-Q 96GB ×2枚構成 ネットワーク on board (2.5GbE x1 /10GbE x1) 筐体+電源 ミドルタワー型筐体+1600W 80PLUS PLATINUM OS Ubuntu 24.04 その他 12A 200V電源ケーブル C19 – C14
インストール作業(GPUドライバー、CUDA Toolkit、cuDNN)キーワード
CUDA Toolkitとは
CUDA Toolkitは、NVIDIAが提供するGPUコンピューティング開発環境です。
C/C++やFortranでのGPUプログラミングを可能にし、ディープラーニングや数値解析などで高速計算を実行できます。cuDNN(CUDA Deep Neural Network library)とは
cuDNNは、NVIDIAが提供する、GPUを用いたディープニューラルネットワーク(DNN)計算を高速化するための高性能ライブラリです。
TensorFlowやPyTorchといった主要フレームワークに組み込まれており、大学・企業の研究者が日常的に利用しています。cuDNNを使う最大のメリットは、フレームワークごとにGPU向けの最適化コードを書く必要がないことです。
NVIDIAがチューニングした演算処理やメモリ管理により、畳み込み演算やプーリング、正規化など、DNNで頻繁に使われる処理を安定して高速に実行できます。事例追加日:2025/11/25
- 事例No.PC-TUKM253379
-
Llama-3対応自然言語処理用ワークステーション
用途:日本語LLM推論、自然言語処理参考価格:1210000円お客さまからのご相談内容
事例No.PC-10873を見ての問い合わせ。
elyza の Llama-3-ELYZA-JP-8B を用いて自然言語処理を行い、文章の要約を実行しているが、現在使用中のPCでは1件あたりの演算に5分以上かかってしまう。
処理時間を短縮するため、新たにPCの導入を検討しており、予算は税込146万円以内を希望している。
大学に提出する参考資料として、パーツ構成や見積額の詳細を知りたい。テガラからのご提案
お客様のご要望を踏まえ、計算時間の短縮を目的として、GPUおよびメモリ性能を重視した構成をご提案いたしました。
LLMを高速に動かすために重要なGPU
LLMの推論処理では、GPUのVRAM容量と演算性能が処理時間に大きく影響します。
特に、十分なVRAM容量があることで、より大規模なモデルをGPU単体で処理できるようになり、効率的な推論が可能となります。
一方、VRAMが不足するとメモリスワップが発生し、GPUとCPU間のデータ転送がボトルネックとなって、処理速度が著しく低下します。例えば、Llama-3-ELYZA-JP-8BをINT8量子化で運用する場合、約17GBのVRAMが必要です。
そのため、最低でも24GB以上のVRAMを搭載することが推奨されています。RTX 5090は、最新のCUDAおよびTensorコアを搭載したモデルで、同じVRAM容量を持つRTX 5000 Adaと比較して、約2倍の推論速度を記録した検証結果が報告されています。
この性能差を踏まえ、今回の構成ではRTX 5090を採用しました。詳細な検証結果は、下記の技術記事をご覧ください。
GeForce RTX 4090との比較検証結果も記載されております。高負荷のLLM推論にも安定して対応できる計算性能を備えているため、実運用環境では処理時間の大幅な短縮が期待できます。
LLM推論におけるメインメモリの重要性
LLMの安定稼働には、GPUのVRAMに加えて、ホスト側メモリの確保が不可欠です。
モデルのロード時にはVRAMを超える一時メモリが必要となる場面があるほか、入力テキストや生成結果の保持にもメインメモリが消費されます。こうした運用条件を踏まえ、本設計では128GB(64GB × 2)のDDR5メモリを標準搭載しました。
さらに空きスロット (4スロット中2スロット未使用) を活用することで、最大256GBまでのメモリ増設が可能です。
将来的なモデルの大規模化やバッチ処理の拡張にも、柔軟に対応できる構成です。このような分野で活躍されている方へ
- 自然言語処理
- 人工知能
- 情報学
- 計算言語学
- 知識情報処理
バッチサイズや量子化設定など、運用条件に応じた最適な構成をご提案いたします。具体的なご用途があれば、ぜひご相談ください。









通常24時間以内に担当者からご連絡いたします
主な仕様
CPU Intel Core Ultra 9 285K 3.70GHz(8C/8T)+3.20GHz(16C/16T) メモリ 合計128GB DDR5 6400 64GB x 2 ストレージ1 2TB SSD M.2 NVMe Gen4 ビデオ NVIDIA GeForce RTX5090 32GB ネットワーク on board(2.5GBase-T x1) Wi-Fi,Bluetooth 筐体+電源 ミドルタワー型筐体 1600W 80PLUS TITANIUM OS Microsoft Windows 11 Professional 64bit キーワード
・Llama-3-ELYZA-JP-8B とは
Llama-3-ELYZA-JP-8Bは、株式会社ELYZAがMeta社の「Llama 3」を基に開発した、日本語に特化した大規模言語モデルです。
80億パラメータというコンパクトさと、日本語らしいニュアンスを捉える力を両立させており、情報工学・計算機科学分野や言語学研究に活用されています。ローカル環境で動作するため、機密データや社内情報を外部に出さずに処理できる点も特長です。事例追加日:2025/8/22
- 事例No.PC-TW2D252130
-

大規模言語モデル計算処理向けマシン
用途:Llama推論、ローカルLLM、Difyアプリケーション開発参考価格:4526500円お客さまからのご相談内容
事例No.PC-10880を見ての問い合わせ。
ローカル環境でLLMを活用するため、LLMの計算に必要なマシン購入を検討している。計算に必要なマシンスペックがわからないため、どのような仕様が必要になるか含めて知りたい。
また、その他必要な周辺機器、指定ソフトウェアのインストール可否を教えてほしい。
Difyと、METAのLlama 3.3 (70B) の使用を想定している。
NVIDIA Geforce RTX 4090 24GB でLlama 3.3を計算させたところVRAM使用率が99%となり不足していることを確認した。テガラからのご提案
事例No.PC-10880をベースに、現行世代のパーツで作成しました。
大規模言語モデル (LLM) の推論や学習をローカル環境で安定稼働させたい研究者・エンジニア向けの仕様です。GPUとしてNVIDIA RTX 6000 Ada 48GBを2基搭載し、AI推論・学習処理を高速化します。
さらに、画面描画用としてRTX A400 4GBを別途採用しているため、計算処理と表示処理を分離し、安定運用が可能です。また、ECC対応DDR5メモリを搭載しており、長時間の計算処理に対する高い信頼性があります。
PCI-E x16スロットを4基備えているため、GPUの追加にも柔軟に対応可能です。
電源には1500W PLATINUMを採用し、生成AIやLLM開発など安定運用が求められる環境でも安心して使用できます。最新GPUを搭載し、ご相談いただいた各種ソフトウェアもインストール済みのため、購入後すぐに研究や開発業務に活用できます。
このような分野で活躍されている方へ
- 計算機科学
- 自然言語処理
- AI工学
- 情報システム開発
- 応用統計学
※本構成はソフトウェアのライセンス・セットアップ費用も含んだ価格です。
掲載されていない仕様や特殊要件についても柔軟に対応いたしますので、ぜひお気軽にご相談ください。通常24時間以内に担当者からご連絡いたします
主な仕様
CPU Intel Xeon W5-2565X 3.20GHz (TB3.0時 最大4.8GHz) 18C/36T メモリ 合計256GB DDR5 5600 REG ECC 32GB x 8 ストレージ 2TB SSD M.2 NVMe Gen4 ビデオ NVIDIA RTX 6000 Ada 48GB x 2基構成
NVIDIA RTX A400 4GB (MiniDisplayPort x 4)ネットワーク on board (2.5GbE x1 /10GbE x1) 筐体+電源 タワー型筐体 1500W 80PLUS PLATINUM OS Microsoft Windows 11 Professional 64bit その他 ソフトウェアインストール
・Dify (v0.15.2+)
・Ollama (v0.5.7+, Desktop 2.139.1733+)
・Llama 3.3 model
・Docker Desktop (企業利用はライセンス要確認)
・Power BIキーワード
・Llamaとは
Llamaは、Meta社が開発した大規模言語モデル群。
Llama 3.3 (70B) などパラメータ数が多いモデルは高性能GPUと大容量メモリを必要とし、ローカル運用時の計算負荷が大きい。
最新論文やモデル情報は研究開発でも注目されている。・Difyとは
Difyは、オープンソースの生成AIアプリケーション開発プラットフォーム。
LLMを活用したアプリ構築を迅速化でき、API連携やチャットボット作成も容易。
LLM推論環境と合わせて導入するケースが増えている。事例追加日:2025/7/9
- 事例No.PC-25000461
-
機械学習・大規模言語モデル (LLM) 処理向けマシン
用途:画像解析、自然言語処理参考価格:3297800円お客さまからのご相談内容
予算330万円 (税込) 未満で、機械学習を用いた画像識別や大規模言語モデルを使用した自然言語処理なども実施可能なマシンを希望する。
想定しているスペックは以下の通り。OS:Ubuntu
メモリ:256GB以上
ストレージ:SSD 1TB以上、HDD 4TB以上
GPU:NVIDIA RTX 6000 Ada 世代 / 48GB以上テガラからのご提案
ご連絡いただいたご要望に合わせて構成を検討しました。
なお、ご提示の条件に対してご予算に余裕がありましたため、より快適な運用を見据えて、SSDおよびHDDの容量をそれぞれ2倍に拡張 (SSD 1TB→2TB、HDD 4TB→8TB) しました。電源要件について
本構成は、将来的な拡張を想定していないGPU1基のみとなっております。
そのため、ご家庭や一般的なオフィス環境における「100V電源」で使用が可能です。
導入時以降にGPUの増設を検討される場合には、適切な電源ユニットや運用環境などを個別にご案内いたします。同一型番のGPU「NVIDIA RTX 6000 Ada 48GB」を2基搭載した仕様の導入事例もございますので、下記ページをご参照ください。
また、LLM要約タスクを用いて、GPU構成ごとの処理性能を比較検証した結果も公開しております。
ぜひ、構成検討の参考にご覧ください。GPUの増設や複数基の搭載に伴って構成全体の消費電力が増加する場合、200V電源環境でのご利用が必要となるケースもございます。
総消費電力の目安として、1600Wの電源ユニットをご利用の場合、200V環境では最大出力の1600W、100V環境ではおよそ1200Wまで対応可能です。
ご提示いただいたご希望に合わせて柔軟なマシンをご提案いたします。掲載内容とは異なる条件でも、お気軽にご相談ください。
通常24時間以内に担当者からご連絡いたします
主な仕様
CPU Intel Xeon W7-2575X 3.00GHz (TB3.0時 最大4.8GHz) 22C/44T メモリ 合計512GB DDR5 5600 REG ECC 64GB x 8 ストレージ1 2TB SSD S-ATA ストレージ2 8TB HDD S-ATA ビデオ NVIDIA RTX 6000 Ada 48GB (DisplayPort x 4) ネットワーク on board (2.5GbE x 1 /10GbE x 1) 筐体+電源 ミドルタワー型筐体 1500W 80PLUS PLATINUM OS Ubuntu 24.04 事例追加日:2025/6/5
- 事例No.PC-11242
-

生物学向け大規模言語モデルの学習用マシン
用途:生物学向け大規模言語モデル (ProteinBERT、 ChemBERTa、 HyenaDNAなど) の学習参考価格:2528900円お客さまからのご相談内容
生物学向け大規模言語モデルの学習用マシンの導入を検討している。
ProteinBERT、 ChemBERTa、 HyenaDNAといった生物学で用いられる大規模言語モデルを事前学習から実行したいと考えている。ProteinBERTはNvidia Quadro RTX 5000、ChemBERTaはNVIDIA Tesla T4、HyenaDNAはNVIDIA A100をそれぞれ学習に使用したとの情報があるため、GPUの性能を重視したい。
予算300万円以内で、上記の用途における計算処理を最も高速化できる構成を提案してほしい。
また、設置場所の制限があるため、筐体サイズはミドルタワー程度で、100V環境で使用可能な構成が望ましい。
希望する条件は以下の通り。
・GPU:性能重視
・電源:100V環境に対応
・筐体:ミドルタワー程度
・予算:300万円以内テガラからのご提案
お客さまご希望の条件に沿った構成をご提案しました。
ご予算・利用環境を踏まえたうえで、GPU性能を重視した構成です。GPUの選定について
GPUはNVIDIA RTX A6000 x2枚を搭載しています。
ProteinBERT開発元の公式サイトによると、学習済みモデルの構築にはNVIDIA RTX5000を用いて1か月ほど要したと記載されています。
A6000はRTX5000より世代が新しく、ラインナップ上でも上位モデルにあたる製品のため、RTX5000よりも高い処理性能が期待できます。例として挙げていただいたNVIDIA Tesla T4は、推論向けとして利用されることが多い製品です。そのため、本構成ではNVIDIA TeslaT4よりも単体性能が高いA6000を採用しています。
NVIDIA A100とRTX A6000の違い
また、NVIDIA A100は、A6000とは異なり、GPGPU専用カードです。
高いfp64性能を持ち科学計算に適した製品ですが、今回のようなDeepLearning用途ではfp64性能が利用されることはほとんどありません。
あわせて、価格に関してもA6000と比較して非常に高額で、かつ専用の筐体でなければ利用できないことから、今回の利用条件や用途におけるマッチングが高くないと判断しました。ストレージに関しては、ProteinBERTの開発元よりユーザー自らモデルの学習を行う場合は1TB以上のストレージ容量を確保することが推奨されているため、2TBのシステムディスク、4TBのデータディスクを搭載しています。
なお、学習中に頻繁なデータアクセスが発生することを想定して、ストレージはすべてSSDとしています。OSはWindows 11を選択しています。
ご使用予定の言語モデルは基本的にはPythonパッケージで提供されているもののため、Pythonを使用可能なOSであれば、ご希望に応じて変更も可能です。本事例の構成は、お客様から頂戴した条件を元に検討した内容です。
いただいた条件に合わせて柔軟にマシンをご提案いたしますので、掲載内容とは異なる条件でご検討の場合でも、お気軽にご相談ください。通常24時間以内に担当者からご連絡いたします
主な仕様
CPU Intel Xeon W5-2455X (3.20GHz 12コア) メモリ 128GB REG ECC ストレージ1 2TB SSD M.2 ストレージ2 4TB SSD S-ATA ビデオ NVIDIA RTX A6000 48GB x2 ネットワーク on board (1GbE x1 /10GbE x1) 筐体+電源 ミドルタワー型筐体 + 1500W OS Microsoft Windows 11 Professional 64bit キーワード
・DeepLearningとは
DeepLearningは機械学習の一種であり、多層のニューラルネットワークを用いて高度なパターン認識や予測を行う手法。一般的に大量のデータを必要とするため、データが豊富な場合に効果的な手法とされている。 また、DeepLeanigは画像認識や音声認識、自然言語処理などの分野で広く用いられている。複雑な特徴や関係性を学習することができるため、従来の機械学習手法よりも高い精度を発揮することができる。・Pythonとは
Pythonは、Python Software Foundation (PSF) が著作権を保持する、オブジェクト指向プログラミング言語。プログラミングの構文がシンプルなため可読性が高く、目的に応じたライブラリやフレームワークといったコンポーネントが豊富に揃っていることも特徴。プログラミングの初学者から上級者に至るまで人気の言語。・BERTとは
BERT (Bidirectional Encoder Representations from Transformers) は、Googleが開発した自然言語処理 (NLP) モデル。与えられた文脈に基づいて単語を理解することができ、言語処理における幅広いタスクに適用される。
また、BERTは事前学習とファインチューニングの2つのフェーズで構成されている。事前学習では、大規模なコーパスから学習された汎用的な言語モデルが作成される。ファインチューニングでは、特定のタスクに適用するために、小規模なデータセットから学習されたモデルが調整される。
従来のNLPモデルに比べて高い精度を示し、複雑なタスクにも対応できることが特徴で、テキスト生成、質問応答、文書分類、言語翻訳などに応用されており、NLPの分野で最も有名なモデルの1つとして広く使われている。・ProteinBERTとは
ProteinBERTは、BERTをベースにしたタンパク質言語モデル。 UniRef90データベース上の最大1億600万のタンパク質で事前学習されており、非常に長いタンパク質配列を含む、ほぼあらゆる長さのタンパク質配列を処理することが可能。・ChemBERTaとは
ChemBERTaは、RoBERTa (BERTの亜種) を用いた、化学構造の表記方法であるSMILES記法の大規模言語モデル。 医薬品設計、化学モデリング、特性予測などに用いられている。・HyenaDNAとは
HyenaDNAは、ヒトゲノムを100万トークンの塩基配列として事前学習した大規模言語モデル。 単一ヌクレオチド単位 (ATGC) でのトークン化により、ヌクレオチド単位での解析が可能。事例追加日:2023/11/09
- 事例No.PC-11098
-
医用画像DeepLearning用マシン
用途:TensorFlow、Keras、Pytorch、CUDAの利用参考価格:600600円お客さまからのご相談内容
医用画像を利用したDeepLearningを行うためのマシンを検討したい。予算60万円の範囲内で可能な構成を提案して欲しい。検討における条件は以下の通り。
・使用するソフトウェア:TensorFlow、Keras、Pytorch、CUDA
・OS:インストールなし (Ubuntu 22.04予定)GPUでの学習を想定しているが、提案の構成がGPUを複数搭載できるか教えて欲しい。
また、GPUメモリの容量とGPUの搭載数のどちらを優先するべきかについても知りたい。テガラからのご提案
第13世代Core i7を搭載した構成をご提案しました。
ビデオカードにはGeforce RTX4080を選択しています。
1ランク上のRTX4090とした場合、ご予算オーバーになってしまうため、コストを優先した選択です。
RTX4080も前世代のRTX3090とほぼ同等のCUDAコア数を搭載しているため、単純な処理性能の面ではハイエンドモデルに位置付けられます。なお、ビデオカードの複数搭載につきましては、ご予算内での対応が難しいことから本件では考慮していません。
本事例の構成はビデオカード x1枚での運用を前提とし、カード増設非対応の構成となっております。
もし、ビデオカード x2枚を搭載可能な構成をご希望の場合は、ベース構成をワークステーション向けに最適化したものへと変更してご提案しますのでお知らせください。
通常24時間以内に担当者からご連絡いたします
検索キーワード
医用画像DeepLearning,TensorFlow,Keras,Pytorch,CUDA Toolkit,ディープラーニングマシン,NVIDIA Geforce RTX4080,機械学習ソフトウェア,インストールなしOS,GPUメモリ容量主な仕様
CPU Core i7-13700K (3.40GHz 8コア + 2.50GHz 8コア) メモリ 32GB ストレージ 1TB SSD S-ATA ビデオ NVIDIA Geforce RTX4080 16GB ネットワーク on board (2.5GBase-T x1) Wi-Fi x1 筐体+電源 タワー型筐体 + 850W OS なし キーワード
・DeepLearningとは
DeepLearningは機械学習の一種であり、多層のニューラルネットワークを用いて高度なパターン認識や予測を行う手法。一般的に大量のデータを必要とするため、データが豊富な場合に効果的な手法とされている。
また、DeepLearnigは画像認識や音声認識、自然言語処理などの分野で広く用いられている。複雑な特徴や関係性を学習することができるため、従来の機械学習手法よりも高い精度を発揮することができる。・TensorFlowとは
TensorFlowはGoogleがオープンソースとして公開している機械学習ライブラリ。PythonやC++など多言語に対応し、CPUやGPUを利用した高速な計算が可能。画像認識や自然言語処理、時系列データ処理といった用途に適しており、事前学習済みのニューラルネットワークを利用できることも特徴。大規模データセットでの学習が行えるため、最新の深層学習研究開発に幅広く用いられている。・Kerasとは
KerasはPythonで書かれたディープラーニングのためのライブラリ。使いやすさと直感的なAPIデザインが特徴で、迅速なニューラルネットのプロトタイピングが可能。バックエンドにTensorFlowやTheanoを利用し、CPUとGPUの両方で動作する。また、Pythonで書かれているため柔軟に拡張ができ、研究開発用途に適している。・CUDA Toolkitとは
CUDA Toolkitは、NVIDIAが提供しているGPU向けのパラレルコンピューティングプラットフォーム。C/C++からNVIDIAのGPUアーキテクチャを利用した高速なパラレルプログラミングが可能。DeepLearningや科学計算、コンピュータグラフィックスなど、様々な分野でGPUの計算能力を活かすことができる。コンパイラ、ライブラリ、デバッガなどのツールが含まれており、SDKとして提供されている。マルチGPU環境もサポートしており、ワークステーションからクラウドまで幅広い環境で活用できる。参考:CUDA Toolkit – Free Tools and Training | NVIDIA Developer ※外部サイトに飛びます
事例追加日:2023/07/21
- 事例No.PC-11075
-
GIS x ビッグデータ処理用マシン
用途:ビッグデータ処理、MCMC処理、Pythonによる自然言語処理 (PyTorch) 、地理情報システムによるネットワーク分析参考価格:3052500円お客さまからのご相談内容
ビッグデータ処理やMCMC処理、Pythonによる自然言語処理 (PyTorch) 、地理情報システムによるネットワーク分析などが可能なワークステーションを導入したい。
高精度なGPUに加えて、ビッグデータ処理にも対応できるCPUが必要だと考えている。
想定しているマシンの規模は以下の通り。・メモリ:出荷時点では128GB程度。最大1TBまで増設可能な構成。
・GPU:NVIDIA RTX A6000を2台搭載し、NVLINKを実装
・使用するソフトウェア:R、Rstudio、Python、ArcGIS、QGIS
・その他:オフィス内の利用に耐えられる静音性テガラからのご提案
Xeon W-3400シリーズの24コアモデルを搭載した構成です。
NVIDIA RTX A6000を2台搭載し、NVLink Bridgeも含めています。メモリは、初期の128GBから将来的に1TBへ拡張する想定ですが、128GB搭載時のメモリはすべて取り外す必要があります。そのため、初期出荷時点のメモリモジュール構成はメモリ拡張を考慮せず、すべてのメモリチャネルを使い切ることを優先しています。
ストレージは暫定的な容量としています。
ビッグデータ処理での利用において、マシン本体側に必要なストレージ容量の目安をご連絡いただければ、それに合わせて変更いたします。
また、ArcGISはキャッシュ領域にストレージを利用しますので、OSやソフトウェアがインストールされるSSDはより高速なNVMe対応製品としています。設置場所がオフィス内であることに留意し、静音性の高い筐体を採用していますが、GPGPUでビデオカードをフル稼働させた場合には、ある程度の大きさの駆動音が発生いたします。さらなる冷却性・静音性を希望される場合、オプションで静音ラックのご用意もございますので、ご相談ください。
稼働音対策をご希望のお客様には、エスアイ社製の静音ラックと合わせたご提案を承っております。
静音性を重視したマシン導入をお考えの際には、気兼ねなくご相談ください。
エスアイ社製 静音ラックの特長
[1]ユーザーの環境とマシンに合わせた専用設計のラックを提供
[2]静音性と安全放熱を高い次元で両立
[3]音響の専門技術を軸としたメーカーなので、静音性の技術力が高い
[4]マシン適合の技術サービスが付帯し、安全運用を約束なお、本事例の構成は、金額にはとらわれず性能を優先した構成です。
メモリチャネル数が8と高性能ですので、コストダウンで最初に見直すポイントはCPUやメモリ周りになると考えられます。 ご予算に応じたプラン提案につきましても、お気軽にご相談ください。通常24時間以内に担当者からご連絡いたします
主な仕様
CPU Xeon W7-3455 (2.50GHz 24コア) メモリ 128GB ストレージ1 4TB SSD M.2 ストレージ2 16TB HDD S-ATA ビデオ NVIDIA RTX A6000 x2 ネットワーク on board (1GbE x1 /10GbE x1) 筐体+電源 タワー型筐体 + 1600W OS Ubuntu 22.04 その他 NVLINK Bridge キーワード
・Rとは
Rとはオープンソース・フリーソフトウェアの統計解析向けプログラミング言語/開発実行環境。統計処理のための計算やグラフ化で利用される。
多くのライブラリが存在するため、ライブラリを呼び出すだけで複雑な手法を扱うことができる。・Rstudioとは
RstudioはRを使用するための統合開発環境。直感的で使いやすいユーザーインターフェースを提供し、プロジェクト管理機能、コードエディター、コードの自動補完、構文のハイライト、デバッガー、プロファイラー、マークダウン文書のサポート、パッケージの管理機能、グラフィックのインタラクティブな表示機能などの多彩な機能を備えている。・Pythonとは
Pythonは、Python Software Foundation (PSF) が著作権を保持する、オブジェクト指向プログラミング言語。プログラミングの構文がシンプルなため可読性が高く、目的に応じたライブラリやフレームワークといったコンポーネントが豊富に揃っていることも特徴。プログラミングの初学者から上級者に至るまで人気の言語。参考:【特集記事】プログラミング言語 Python その人気の理由は?- Python プログラミングを加速するツールたち ※弊社オウンドメディア「TEGAKARI」に飛びます
・ArcGISとは
ArcGISは地理情報システム(GIS)の代表的なソフトウェアプラットフォームである。地理データの収集・管理・解析・可視化を行うことができ、世界の多くの組織でGISとして利用されている。デスクトップ製品としてArcGIS ProやArcMap、サーバー製品としてArcGIS Enterprise、開発者向けにAppStudioやArcGIS API for Python、モバイルではArcGIS QuickCaptureやExplorerなどがある。世界中の行政機関や企業でGISとして広く利用されている。・QGISとは
QGISは、QGIS Development Teamにより開発されたオープンソースのGISソフトウェア。ArcGISに似たインターフェイスで空間データの可視化・編集・解析に対応している。機能面はArcGISと比較して限定的だが、無料で利用できる点とコミュニティサポートから個人・教育目的での利用に適しており、世界的に利用されている。・NVLINKとは
NVLinkはNVIDIAが開発したGPU間の高速インターコネクト技術。NVLinkを採用したGPUはPCI Expressよりも高速な通信帯域幅と速度を実現し、GPU間のデータ送受信の効率が大幅に向上する。NVLinkはAIや高性能計算分野において、大規模な並列処理の効率を高める技術として採用されることがある。事例追加日:2023/06/29
- 事例No.PC-10992
-

AIサービス用マシン
用途:サービス開発を目的としたDeepLearning実験参考価格:1610400円お客さまからのご相談内容
事例No.PC-10880を見ての問い合わせ。
以下の条件でDeep Learningの実験用マシンを検討したいので、構成を提案して欲しい。・CPU:Core i9
・メモリ:128GB
・ストレージ1:1TB SSD
・ストレージ2:2TB HDD
・GPU:RTX 4090 x2台
・OS:Ubuntu 20.04
・使用するソフトウェア:R、Rstudio、Python、BayoLinkS
・予算:100万円以内 難しい場合でも、どの程度の金額になるか知りたい
・その他:PyTorch 1.9 または2.0を使用テガラからのご提案
ご参照の事例をご予算に合わせてカスタムした構成です。
本事例の構成はPC-10880とは異なり、電源ユニット1台で動作しますが、100V給電ではフル稼働時に電源容量に余裕がなくなるため、200V給電での利用を推奨します。
また、RTX4090を2台搭載するためには、PCI-E x16スロットを2本用意する必要があります。CPUをCore i9とする場合、PCI-Eレーン数を必要分確保することが難しいため、対応可能なXeon仕様としています。本事例の構成は、お客様から頂戴した条件を元に検討した内容です。
掲載内容とは異なる条件でご検討の場合でも、お気軽にご相談ください。通常24時間以内に担当者からご連絡いたします
検索キーワード
AIサービス用マシン,Deep Learning実験,Core i9,128GBメモリ,1TB SSD,2TB HDD,RTX 4090,Ubuntu 20.04,R、Rstudio、Python、BayoLinkS,PyTorch 1.9主な仕様
CPU Xeon Silver 4314 (2.40GHz 16コア) メモリ 128GB REG ECC ストレージ1 1TB SSD S-ATA ストレージ2 4TB HDD S-ATA ビデオ NVIDIA Geforce RTX4090 x2 ネットワーク on board (1GbE x1 10GBase-T x1) 筐体+電源 タワー型筐体 + 1600W OS Ubuntu20.04 その他 200V対応ケーブル
キーワード
・PCI Express (PCI-E/PCIe) とは
PCI ExpressはPCやサーバーなどのシステムで高速なデータ転送を行うためのインターフェース規格。レーンと呼ばれる単位で送受信する。PCI-Eは1本の送信用差動ペアと1本の受信用の差動ペアで構成される。1レーンあたりの転送速度はバージョンによって異なるが、PCI-E 5.0では1レーン当たり32Gbpsの転送が可能。
また、PCI-E x1スロットには1本のレーンがあり、PCI-E x4スロットには4本のレーンがある。したがって、PCI-E x4スロットはPCI-E x1スロットの4倍の転送速度を持つ。
ビデオカードは高速なデータ転送を必要とするため、通常は最大レーン数であるPCI-E x16スロットに接続される。・DeepLearningとは
DeepLearningは機械学習の一種であり、多層のニューラルネットワークを用いて高度なパターン認識や予測を行う手法。一般的に大量のデータを必要とするため、データが豊富な場合に効果的な手法とされている。
また、DeepLearnigは画像認識や音声認識、自然言語処理などの分野で広く用いられている。複雑な特徴や関係性を学習することができるため、従来の機械学習手法よりも高い精度を発揮することができる。参考:【特集記事】機械学習ってなんだろう ※弊社オウンドメディア「TEGAKARI」に飛びます
・PyTorchとは
PyTorchはPythonで書かれたオープンソースの機械学習ライブラリ。ニューラルネットワークの構築やトレーニングにおいて、高速かつ柔軟な開発を可能にすることを目的としている。また、Tensorと呼ばれる多次元配列を扱うことが可能で、GPUを用いて高速な演算を行うことが可能。
その他、多くのモデルアーキテクチャをサポートしており、様々な種類のニューラルネットワークをを簡単に構築することができる。加えて、GPUをサポートしているため、大規模なデータセットを用いた学習を効率的に行うことができる。事例追加日:2023/05/18
- 事例No.PC-10970
-
音声解析研究用マシン
用途:音声認識モデル「Whisper」の利用参考価格:1372800円お客さまからのご相談内容
電話用の音声認識システム開発を行うため、OpenAIの「Whisper」を利用するPCを検討している。
検討においては、以下の条件を想定している。・CPU:Xeon W-2225
・メモリ:64GB REG ECC
・ストレージ:SSD 2TB M.2
・ビデオ:NVIDIA RTX A6000
・OS:Ubuntu 22.04
・その他:将来の増設に対応できるGPUと電源を希望上記に近いPC構成を提案して欲しい。
テガラからのご提案
ご連絡いただいた条件を踏まえて構成を検討しました。
Whisper利用時のスペック選定
「Whisper」はGPUを利用するので、GPUの処理能力を重視した選定が良いかと存じます。
搭載するGPUは、お客様よりご希望いただいたA6000もしくはRTX6000 Adaを用いた構成が理想です。現状ではRTX6000 Adaのコストがかなり大きいため、A6000を採用した構成としています。ただし、A6000自体の供給もそれほど長くないと考えられるので、将来のGPU増設が1年以上先である場合には、RTX6000 Adaがベストです。なお、GPU x1枚構成のままで将来の増設を考慮しない場合には、CPUをCore-i系にすることでコストを抑えることができます。
本事例の構成は、お客様から頂戴した条件を元に検討した内容です。
掲載内容とは異なる条件でご検討の場合でも、お気軽にご相談ください。通常24時間以内に担当者からご連絡いたします
主な仕様
CPU Xeon W-2225 (4.10GHz 4コア) メモリ 64GB REG ECC ストレージ 2TB SSD M.2 ビデオ NVIDIA RTX A6000 ネットワーク on board (10/100/1000Base-T x1 5G x1) 筐体+電源 ミドルタワー筐体 + 1600W OS Ubuntu 22.04 キーワード
・OpenAI Whisperとは
WhisperはOpenAIが開発したチャットボットプラットフォーム。自然言語処理技術を駆使して、顧客との会話を自動的に処理し、カスタマーサポートや営業活動に利用することができる。また、自社開発したアプリケーションとWhisperをAPIを使用して統合することも可能。事例追加日:2023/04/27
- 事例No.PC-10873
-
自然言語処理モデル用ワークステーション
用途:BERTのFine-tuningおよびNVIDIA Clara Parabricks参考価格:1466300円お客さまからのご相談内容
手持ちのGPU x2台 (RTX A6000 2台またはA100 2台)を使用するためのマシンを購入したい。
希望する条件は以下の通り。・100Vの電源環境で動作する構成を希望
・消費電力はできるだけ小さくしたい
・居室で使用するため、GPU使用時以外は静音が望ましい。ただし、GPU使用時の稼働音は許容する
・用途はBERTのFine-tuningおよびNVIDIA Clara Parabricks
・予算は150万円予算は年度を超えても大丈夫だが、できるだけ早く入手できると嬉しい。
テガラからのご提案
ご要望に合わせて構成を検討しました。
消費電力を意識して、Ryzen Threadripper構成としています。搭載するGPUはRTX A6000を想定しています。
A100はGPU本体に冷却FANがないため、GPU冷却機構を持つGPGPUサーバー用の筐体が必須となり、ご予算内での実現は難しいとお考えください。100V環境で利用できる電源容量
電源ユニットは1600W対応品としていますが、100V環境での利用では1300W程度までが利用可能です。 入力が最大100V/15Aの交流に対して直流への変換時にロスがあり、80+の最大変換効率であるTITANIUMであっても、100%動作時の変換効率は90%です。100V/15A時は1500W x0.9として1350Wが理論上の上限となります。
上記を前提に、CPU側は極力消費電力が少ないことが望ましいと考えられるため、1CPU構成のThreadripper構成をご提案しました。 また、本構成は1CPU構成のため物理的に筐体内部スペースの余裕がありますので、200V環境で利用する場合にはRTX A6000を合計3台利用することができます。
本事例の構成は、お客様から頂戴した条件を元に検討した内容です。
掲載内容とは異なる条件でご検討の場合でも、お気軽にご相談ください。稼働音対策をご希望のお客様には、エスアイ社製の静音ラックと合わせたご提案も承っております。
静音性を重視したマシン導入をお考えの際には、気兼ねなくご相談ください。エスアイ社製 静音ラックの特長
[1]ユーザーの環境とマシンに合わせた専用設計のラックを提供
[2]静音性と安全放熱を高い次元で両立
[3]音響の専門技術を軸としたメーカーなので、静音性の技術力が高い
[4]マシン適合の技術サービスが付帯し、安全運用を約束通常24時間以内に担当者からご連絡いたします
検索キーワード
自然言語処理モデル用ワークステーション,BERT Fine-tuning,NVIDIA Clara Parabricks,GPU x2台,RTX A6000,A100,100V電源環境,消費電力,静音,予算150万円主な仕様
CPU AMD Ryzen ThreadripperPRO 5975WX (3.60GHz 32コア) メモリ 256GB REG ECC ストレージ 1TB SSD M.2 ビデオ on board (VGAx1) ネットワーク on board (1GbE x1 10GBase-T x1) 筐体+電源 タワー型筐体 + 1600W OS Ubuntu 20.04 キーワード
・BERTとは
BERT (Bidirectional Encoder Representations from Transformers) は、Googleが開発した自然言語処理 (NLP) モデル。与えられた文脈に基づいて単語を理解することができ、言語処理における幅広いタスクに適用される。
また、BERTは事前学習とファインチューニングの2つのフェーズで構成されている。事前学習では、大規模なコーパスから学習された汎用的な言語モデルが作成される。ファインチューニングでは、特定のタスクに適用するために、小規模なデータセットから学習されたモデルが調整される。
従来のNLPモデルに比べて高い精度を示し、複雑なタスクにも対応できることが特徴で、テキスト生成、質問応答、文書分類、言語翻訳などに応用されており、NLPの分野で最も有名なモデルの1つとして広く使われている。・Fine-tuningとは
Fine-tuningとは、事前学習済みの機械学習モデルを特定のタスクに適用するために、タスクに関連するデータセットを用いてモデルを微調整すること。例えば、自然言語処理の場合、大規模なコーパスから学習した汎用的な言語モデルを、特定のテキスト分類タスク (感情分析、スパム検出、トピック分類など) に適用することができる。この場合、モデルは特定の分類タスクに関連する少量のデータセットから学習され、最終的には特定のタスクに最適化される。
Fine-tuningによって、大量のデータを必要とせずに、既存の汎用的なモデルを特定のタスクに適用することができる。・NVIDIA Clara Parabricksとは
NVIDIA Clara Parabricksは、GPUベースの高速なゲノム解析ソフトウェア。ゲノム解析のタスクを大幅に高速化するために、GPUアクセラレーションを利用している。
配列アラインメント、バリアントコール、ゲノムアセンブリなどのタスクに使用されるソフトで、高速な処理速度と高い精度を実現し、短い時間で大量のデータを処理することができる。
また、ハードウェアに依存しないアルゴリズムを採用しているため、様々なGPUプラットフォーム上で動作する。事例追加日:2023/04/13
ご注文の流れ
 |
お問い合わせフォームよりご相談内容をお書き添えの上、 お問い合わせください。 (お電話でもご相談を承っております) |
 |
弊社より24時間以内にメールにてご連絡します。 |
 |
必要に応じてメールにて打ち合わせさせていただいた上で、 メール添付にてお見積書をお送りします。 |
 |
お見積もり内容にご納得いただけましたら、メールにてご注文ください。 ご注文確定後、必要な部材を手配し PCを組み立てます。 (掛売りの場合、最初に新規取引票のご記入をお願いしております) |
 |
動作チェックなどを行い、納期が確定いたしましたらご連絡いたします。 (納期は仕様や製造ラインの状況により異なります) |
 |
お客様のお手元にお届けいたします (ヤマト運輸/西濃運輸) |
お支払い方法
お支払い方法は、お見積もりメール・お見積書でもご案内しています。
| 法人掛売りのお客様 |
| 原則として、月末締、翌月末日払いの後払いとなります。 |
| 学校、公共機関、独立行政法人のお客様 |
| 納入と同時に書類三点セット(見積書、納品書、請求書)をお送りしますのでご請求金額を弊社銀行口座へ期日までにお振込み願います。 先に書面での正式見積書(社印、代表者印付)が必要な場合はお知らせください。 |
| 企業のお客様 |
| 納品時に、代表者印つきの正式書類(納品書、請求書)を添付いたします。 ご検収後、請求金額を弊社銀行口座へお支払い期日までにお振込み願います。 |
| 銀行振込(先振込み)のお客様 |
| ご注文のご連絡をいただいた後、お振込みを確認した時点で注文の確定とさせていただきます。 |
修理のご依頼・サポートについて
弊社製PCの保証内容は、お見積もりメールでもご案内しています。
■お問合せ先
テガラの取り扱い製品に関する総合サポート受付のWEBサイトをご用意しております。
テガラ株式会社 サポートサイト
※お問い合わせの際には、「ご購入前」と「ご購入後」で受付フォームが分かれておりますので、ご注意ください。
| メール | support@tegara.com |
| 電話 | 053-543-6688 |
■テグシスのサポートについて
保証期間内の修理について
保証期間内におけるハードウェアの故障や不具合につきましては、無償で修理いたします。
ただし、お客様による破損や、ソフトウェアに起因するトラブルなど保証規定にて定める項目に該当する場合は保証対象外となります。
保証期間経過後も、PCをお預かりしての初期診断は無料で実施しております。
無料メール相談
PCの運用やトラブルにつきまして、メールでのご相談を承ります。経験・知識の豊富な技術コンサルタントが無料でアドバイスいたします。
※調査や検証が必要な場合はお答えできなかったり、有償対応となることがあります
オプション保証サービス
| 「あんしん+」 もしもの時の延長保証サービス |
|
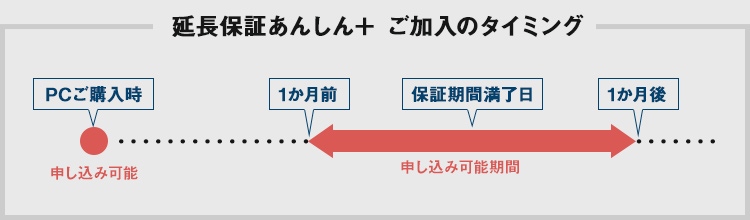
PCのご購入時にトータル5年までの延長保証をご選択いただけます。また、ご購入後にも延長保証を申し込むことができます。
|
| HDD返却不要サービス |
|
保証期間内にPCのHDD(SSD)が故障した場合、通常、新品のHDDとの交換対応となり、故障したHDDはご返却いたしません。 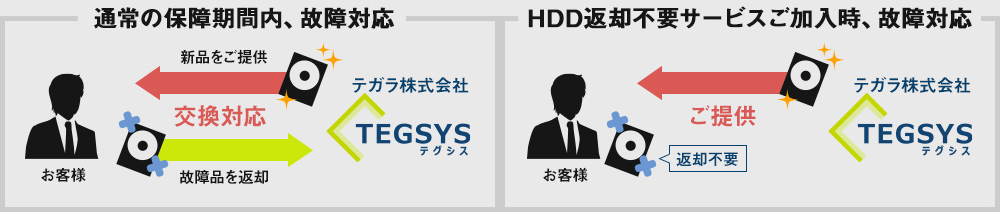
|

| オンサイト保守サポート | |
|
故障発生時、必要に応じエンジニアスタッフが現地へ訪問し、保守対応を行うサービスです。
|
「お客様だけのオーダーメイドPC」を製作しています。
用途に応じた細かなアドバイスや迅速な対応がテガラの強みです。
上記の仕様はテガラでお客様に提案したPC構成の一例です。
掲載内容は提案当時のものであり、また使用する部材の供給状況によっては、現在では提供がむずかしいものや、部材を変更してのご提案となる場合がございます。
参考価格については、提案当時の価格(送料込・税込)になります。
ご相談時期によっては価格が異なる場合がございますので、あらかじめご了承ください。



