- 事例No.PC-TUKJ254141
-

医用画像AI解析ワークステーション (MRI対応)
用途:深層学習、医用画像解析、MRIセグメンテーション参考価格:1048300円お客さまからのご相談内容
PC-11098を見ての問い合わせ。
深層学習を用いた医用画像のセグメンテーションを行うため、50〜100万円の予算で、高解像度画像を大量に扱えるPCを導入したい。
画像サイズ640×640で数万枚を学習させる想定で、RTX 4090や5090といった高性能GPUの採用を考えている。
画像データ量が多いため、数TB規模のストレージ容量も備えてほしい。通常24時間以内に担当者からご連絡いたします
テガラからのご提案
若手研究支援キャンペーン(~2026年3月末)対象のため、オーダーメイドPCを税込価格から5%割引でご提案しました。
GPUの選定
画像サイズとサンプル数の多さを考慮し、まずVRAM容量を重視しました。
大規模データの学習では、バッチサイズを大きく確保する必要があるため、32GB VRAMを持つGeForce RTX 5090を選定しました。
これにより、負荷の高いモデルでも安定した処理が可能です。CPUとメモリについて
本構成では、ご予算内でGPU性能を重視した仕様としています。
そのためCPUはコストバランスを考慮し、Core Ultra 7 265Kを採用しました。
メモリは 64GB (32GB×2) を搭載し、空きスロット2基により、最大128GBまで増設可能です。
大量の画像を扱う場面でも、メモリ不足による学習停止のリスクを抑えられます。ストレージ
サンプル数が多い用途では、読み込み速度がボトルネックになりやすいため、NVMe SSDを採用しました。
OS用に1TB SSD M.2、学習データ用のワークスペースとして4TB SSD M.2を別途搭載しています。このような分野で活躍されている方へ
- 医用画像解析
- 放射線医学
- AI医療工学
- コンピュータビジョン
- 機械学習工学
テガラのオーダーメイド PC 製作サービスは、導入時の用途に加え、将来的な研究規模の拡大を見据えたシステムの拡張にも対応しています。
各種ソフトウェア要件に応じた構成のご提案はもちろん、研究環境全体の構築に関するご相談も承っています。
お客様のニーズに合わせて最適なソリューションをご提供しますので、どうぞお気軽にお問い合わせください。





通常24時間以内に担当者からご連絡いたします
主な仕様
CPU Intel Core Ultra 7 265K 3.90GHz(8C/8T)+3.30GHz(12C/12T) メモリ 合計64GB DDR5 6400 32GB x 2 ストレージ1 1TB SSD M.2 NVMe Gen4 ストレージ2 4TB SSD M.2 NVMe Gen4 ビデオ NVIDIA GeForce RTX5090 32GB ネットワーク on board(2.5GBase-T x1) Wi-Fi,Bluetooth 筐体+電源 ミドルタワー型筐体+1500W 80PLUS PLATINUM OS Microsoft Windows 11 Professional 64bit 保証 TEGARA 若手研究者応援キャンペーン 特典A (~2026年3月末) 事例追加日:2026/3/6
- 事例No.PC-TW2S254295
-

Alohaロボット用ワークステーション
用途:模倣学習用オープンソースロボットアーム「Aloha Stationary 」や「Aloha mobile」の利用参考価格:2476100円お客さまからのご相談内容
事例No.PC-TUKJ253604を参考に、模倣学習用オープンソースロボットアーム「Aloha Stationary」や「Aloha mobile」の動作を前提としたワークステーションを検討したい。
具体的には、USBポートを6口以上備え、RTX PRO 6000 Blackwell Max-Qを搭載した構成を希望する。Ubuntu 20.04の利用を想定しつつ、高速ストレージと十分なメモリ容量も重視したい。
通常24時間以内に担当者からご連絡いたします
テガラからのご提案
お客様の用途が「Aloha Stationary」や「Aloha mobile」の利用に特化していることを踏まえ、安定した周辺機器接続と高いGPU性能を両立できる構成をご提案しました。USBポート数や拡張性の要求が明確だったため、その点を中心に最適化しています。
USBポート構成について
PC背面にUSB 3.0以上のポートを6口以上用意するため、マザーボード標準ポートに加えて拡張カードで合計8つのUSB 3.2ポートを実装しています。
ロボティクス用途では複数のカメラ・センサー類を同時接続するケースが多いため、物理ポートの余裕は実運用上の安定性につながります。
GPU の選定について
ご要望いただいたNVIDIA RTX PRO 6000 Max-Q (96GB) を採用した構成です。大容量VRAMにより、ロボット制御や機械学習モデルの推論処理を安定して実行できます。
CPU・メモリ・ストレージ構成
CPU は Xeon W5-2545 (12コア) を採用し、GPU と並行して処理を行うロボティクスワークロードに十分な性能を確保しています。メモリは 128GB の ECC DDR5 を搭載し、長時間の連続運転や大規模データ処理でも信頼性を担保します。ストレージは 1TB NVMe Gen4 SSD を用いて高速な読み書きを実現しました。
OS について
Ubuntu 20.04 を希望されていましたが、今回の構成では動作検証が完了していないため、互換性が高い Ubuntu 22.04 をご案内しました。最新ハードウェアを利用する場合、カーネルやドライバの対応状況を踏まえたOS選定が安定動作のポイントとなります。
ロボティクス分野での研究開発に必要な拡張性・信頼性・GPU性能をバランスよく備えた構成となっており、周辺機器が多い環境でも安心して運用いただける内容です。
テガラのオーダーメイドPC製作サービスは、導入時の用途に加え、将来的な研究規模の拡大を見据えたシステムの拡張にも対応しています。
各種ソフトウェア要件に応じた構成のご提案はもちろん、研究環境全体の構築に関するご相談も承っています。
お客様のニーズに合わせて最適なソリューションをご提供しますので、どうぞお気軽にお問い合わせください。





通常24時間以内に担当者からご連絡いたします
主な仕様
CPU Intel Xeon W5-2545 3.50GHz (TB3.0時 最大4.7GHz) 12C/24T メモリ 合計128GB DDR5 5600 REG ECC 32GB x 4 ストレージ 1TB SSD M.2 NVMe Gen4 ビデオ NVIDIA RTX PRO6000 Max-Q 96GB ネットワーク on board (2.5GbE x1 /10GbE x1) 筐体+電源 ミドルタワー 1000W 80PLUS PLATINUM OS Ubuntu 22.04 その他 USB 3.2 Gen 1 Type-A x4ポート 拡張カード (合計8ポート) キーワード
・Aloha Stationaryとは
Aloha Stationaryは、Uniposが提供する固定型AIロボティクス研究プラットフォーム。双腕ロボットアームとセンサーモジュールを統合し、マニピュレーション学習、模倣学習(Imitation Learning)、強化学習(Reinforcement Learning)、視覚認識AIモデルの検証など幅広いロボット研究に対応する。高精度なエンドエフェクタ制御と安定したベース構造により、精密作業や実世界タスクのデータ収集が効率的に行える。・Aloha Mobileとは
Aloha Mobileは、Uniposが提供する移動型AIロボティクス研究プラットフォーム。自律移動ベース上に双腕マニピュレーターを搭載し、実世界環境におけるモバイルマニピュレーション、模倣学習、強化学習、物体操作タスクのデータ収集に最適化されている。移動制御とマニピュレーション制御を統合した研究が可能で、サービスロボット開発や環境適応型AIの検証にも有効。事例追加日:2026/02/16
- 事例No.PC-TCPS254088
-

AI開発用GPUサーバー
用途:大規模言語モデルを活用した生成AIをローカル環境で運用参考価格:23881000円お客さまからのご相談内容
社内で大規模言語モデルを活用するため、ローカル環境で運用できる生成AI用ワークステーションの構築を検討したい。使用するソフトウェアはOllama、LM Studio、Dify、Pythonを想定。
CPU はコア数を十分に確保できるモデルを選定し、メモリは最低 1TB、可能であれば 2〜4TB クラスまで拡張しようと考えている。
GPU は NVIDIA RTX Pro 6000 Blackwell を複数枚搭載可能な構成を前提とし、搭載可能な最大枚数で運用したい。
OS は Ubuntuとし、100V 電源環境で動作することを条件とする。
ストレージは可能な限り大容量の NVMe SSD を搭載可能な最大数まで搭載し、全体として高い処理性能と拡張性を確保したい。予算 2,000 万円程度で構成を提案して欲しい。
通常24時間以内に担当者からご連絡いたします
テガラからのご提案
LLM推論・生成AI処理に最適化したCPU / メモリ構成
本構成では、生成AIやローカルLLMの運用に必要となる CPU コア数とメモリ帯域を重視しています。大規模モデルを効率的に処理するためには、GPU性能だけではなく、CPUの多コア性能と大量メモリへのアクセス性能が重要です。
そのため、最新世代のサーバー向けCPUを採用し、多コア処理能力と大容量メモリの両立を図っています。当初は1TBメモリ構成を想定していましたが、将来的なモデル拡張やRAGワークロードへの対応を見据え、今回は搭載可能な最大容量である4TBの構成でご提案しています。
RTX Pro 6000 Blackwell を採用した高密度 GPU 構成
お客様が複数の NVIDIA RTX Pro 6000 Blackwell を搭載したいと希望されていたため、4Uラックマウント筐体を採用し、最大枚数のGPUを安定して運用できるマザーボード構成を選定しました。
PRO 6000クラスのGPUを複数枚搭載する場合には、PCIeレーン数、発熱対策、電源容量などが大きな制約となります。本構成ではこれらの要件をすべて満たし、高密度なGPUサーバーとして安定したAI計算処理を実現します。
NVMeストレージの大容量化とRAID構成
可能な限り大容量のNVMe SSDを最大数搭載したい、という要望に対し、システム用SSDとは別に複数枚のNVMe SSDを搭載し、読み書き速度と冗長性を両立する構成をご提案しています。
この構成により、研究データやEmbeddingキャッシュを高速に扱え、RAG環境やDify・Ollamaなどのローカル推論環境で高いパフォーマンスを発揮できます。
電源環境 (100V希望 → 200V対応への変更)
当初は「100V環境で運用したい」とご相談いただきましたが、GPU多数搭載構成では100Vでは電源容量が不足するため、200V環境を整備される方針に変更となりました。
これにより、サーバー向け電源ユニットを採用できるようになり、マシン全体の安定性と将来拡張性を確保しています。

通常24時間以内に担当者からご連絡いたします
主な仕様
CPU Intel Xeon 6515P 2.30GHz(TB 3.80GHz) 16C/32Tx 2 メモリ 合計4TB DDR5-6400 REG ECC 128GB x 32 ストレージ1 7.68TB U.2 NVMe SSD ストレージ2 15.36TB U.2 NVMe SSD ×5(RAID5) ビデオ NVIDIA RTX PRO 6000 BW Server Edition x 4 ネットワーク ネットワークカード 10GbE RJ45 2ポート 筐体+電源 4Uラックマウント筐体 3200W/200V リダンダント電源(3+1) OS Ubuntu 24.04 その他 RAIDカード Broadcom MegaRAID
レールキット一式
3年センドバック保証 (標準保証1年+延長保証2年)キーワード
・Ollamaとは
Ollamaは、ローカル環境で大規模言語モデル (LLM) を高速に実行できるオープンソースプラットフォーム。GPU最適化やモデルの軽量化が施されており、PythonやWebアプリケーションとの統合も容易。プライバシー保護が求められる企業環境や研究用途において、質量分析データ処理の自動化、ペプチド同定支援、解析スクリプト生成などにも応用可能。・LM Studioとは
LM Studioは、PCローカルで大規模言語モデルを管理・実行するための統合型アプリケーション。GUIでモデルのダウンロード、推論、プロンプト操作を完結でき、研究用スクリプト生成や質量分析 (MS/MS) データ解析ワークフロー構築の補助にも役立つ。ローカル推論によるセキュアなAI環境を必要とする技術者に最適。・Difyとは
Difyは、ノーコード/ローコードでAIアプリを構築できる統合プラットフォーム。RAG (検索拡張生成) 、ワークフロー自動化、モデル切替などが容易で、研究現場のレポート生成、質量分析データ解釈支援ツールの試作、ペプチド同定ヘルパーAIの構築などにも利用可能。クラウドとローカルの両方に対応。・Pythonとは
Pythonは、科学技術計算からAI・機械学習、質量分析データ解析、ペプチド同定アルゴリズム開発まで幅広く利用される汎用プログラミング言語。NumPy、SciPy、pandas、pyteomicsなど豊富なライブラリにより、グリコペプチド解析やMS/MSスペクトル処理の自動化が容易。研究者・エンジニアに必須の開発基盤。事例追加日:2026/2/12
- 事例No.PC-TW2M253280
-
大容量VRAM搭載LLMローカル検証用ワークステーション
用途:ローカル環境でのLLM検証 (Ollama)参考価格:5127430円お客さまからのご相談内容
大規模言語モデル(LLM)のローカル検証を目的にした、高性能PCを導入したい。
VRAM容量は不問、可能な限り多くの高性能GPUを搭載した構成を希望する。
予算は250万〜500万円程度で、Ollamaの利用を想定。
GPUドライバー、CUDA ToolkitおよびcuDNNのプリインストールも依頼したい。
環境は、200V電源の使用が可能。テガラからのご提案
GPUの選定について
今回の用途では、GPU性能とVRAM容量の両立が重要です。
LLMによっては140GB程度のVRAMが必要となることもあるため、NVIDIA RTX PRO 6000 Max-Q(96GB)を2枚搭載する構成をご提案しました。
さらに、3枚目のRTX PRO 6000 Max-Qの増設にも対応できるよう、空きPCIeスロットを確保した設計です。テグシスでは LLM における GPU 性能差をまとめた技術記事を公開しています。
前編では RTX 5090 / RTX 4090 / RTX 5000 Ada の実測比較を、続編では RTX PRO 6000 Max-Q を加えた検証 をご紹介しています。
詳細な検証結果は、下記をご覧ください。

メモリ構成と拡張性
LLMの推論では、VRAMを十分に確保することが前提となり、あわせてシステムメモリも同程度以上の大容量が求められます。
本構成では、256GB (64GB×4枚) のメモリを実装し、空きスロットには同容量 (64GB) のモジュールを増設可能です。将来的に3枚目のGPUを増設する場合、VRAMの総量は 96GB × 3 = 288GB となります。
その際には、空きスロットを活用してメモリを増設することで、適切なシステムメモリを無理なく満たせます。
これにより、GPU増設後もボトルネックを避けて、安定したデータ処理を実現できます。ソフトウェアの事前環境構築
GPUドライバー、CUDA Toolkit、cuDNNを適切なバージョンでプリインストールし、即時利用可能な環境で納品します。
PyTorchなどのフレームワークは、お客様によるセットアップを予定していますが、当社でも導入実績があり、必要に応じてご相談も承ります。このような分野で活躍されている方へ
- 人工知能
- 自然言語処理
- 機械学習
- 計算機科学
- 情報システム
テガラのオーダーメイドPC製作サービスは、導入時の用途に加え、将来的な研究規模の拡大を見据えたシステムの拡張にも対応しています。
各種ソフトウェア要件に応じた構成のご提案はもちろん、研究環境全体の構築に関するご相談も承っています。
お客様のニーズに合わせて最適なソリューションをご提供しますので、どうぞお気軽にお問い合わせください。
通常24時間以内に担当者からご連絡いたします
主な仕様
CPU Intel Xeon W3-2525 3.50GHz (TB3.0時 最大4.5GHz) 8C/16T メモリ 合計256GB DDR5 5600 REG ECC 64GB x 4 ストレージ 1TB SSD S-ATA ビデオ NVIDIA RTX PRO6000 Max-Q 96GB ×2枚構成 ネットワーク on board (2.5GbE x1 /10GbE x1) 筐体+電源 ミドルタワー型筐体+1600W 80PLUS PLATINUM OS Ubuntu 24.04 その他 12A 200V電源ケーブル C19 – C14
インストール作業(GPUドライバー、CUDA Toolkit、cuDNN)キーワード
CUDA Toolkitとは
CUDA Toolkitは、NVIDIAが提供するGPUコンピューティング開発環境です。
C/C++やFortranでのGPUプログラミングを可能にし、ディープラーニングや数値解析などで高速計算を実行できます。cuDNN(CUDA Deep Neural Network library)とは
cuDNNは、NVIDIAが提供する、GPUを用いたディープニューラルネットワーク(DNN)計算を高速化するための高性能ライブラリです。
TensorFlowやPyTorchといった主要フレームワークに組み込まれており、大学・企業の研究者が日常的に利用しています。cuDNNを使う最大のメリットは、フレームワークごとにGPU向けの最適化コードを書く必要がないことです。
NVIDIAがチューニングした演算処理やメモリ管理により、畳み込み演算やプーリング、正規化など、DNNで頻繁に使われる処理を安定して高速に実行できます。事例追加日:2025/11/25
- 事例No.PC-TTPJ253583
-
機械学習・地震波動解析向けワークステーション
用途:機械学習、数値計算 (PyTorch、TensorFlow、Paraview、HBI、OpenSWPC、SPECFEM、MPI、OpenMP)参考価格:5198600円お客さまからのご相談内容
100V環境で使用可能なワークステーションの導入を検討している。予算は約500万円。
用途は機械学習と数値計算。
使用予定のソフトウェアは、PyTorchやTensorFlowなどの機械学習ライブラリに加え、OpenSWPC、SPECFEM、hbi、自作のMPI/OpenMPコードによる並列計算コード。
希望するハードウェアスペックは以下の通り。・CPU:64コア以上
・メモリ:256GB以上(帯域幅も重視)
・GPU:VRAM 96GB以上
・SSD:高速I/O対応、4TB以上テガラからのご提案
並列計算に最適なCPU構成
数値計算に最適なCPUとして、64コア128スレッドのRyzen Threadripper PRO 9985WXを採用しています。
多くのコア数に加え、ベースクロック 3.20GHzという高い動作周波数により、MPIやOpenMPを活用した並列処理を効率的に実行できます。
また、8チャネル対応のDDR5メモリにより、メモリ帯域のボトルネックを軽減しており、複数のプロセスを同時に実行する場合でも、安定した処理が可能です。メモリ構成について
OpenSWPCやSPECFEMなど、大規模な行列データを扱う波動解析ソフトでは、十分なメモリ容量と高速なアクセス性能が求められます。
本構成ではDDR5-5600 REG ECC 512GB(64GB×8枚)を搭載し、容量・帯域幅ともに余裕ある環境を実現しています。
複雑な数値計算や並列処理においても、安定したパフォーマンスで計算処理を行えます。GPUの選定と拡張性
機械学習用途として、GPUにはVRAM 96GBのRTX PRO 6000 Max-Qを選定しています。
大容量のグラフィックメモリは、深層学習だけでなく、GPUを利用する技術計算にも適しており、幅広い解析処理に活用できます。
SPECFEM3D Cartesianの解析では、NVIDIA公式にてマルチGPUによる性能向上が報告されています。本構成は100V環境での単体運用を想定しており、200V環境が整えば2枚目のGPU増設も可能です。
あらかじめ1600W電源を搭載しているため、将来的なGPU拡張にもスムーズに対応できます。ストレージとI/O性能
解析に必要な高速I/Oを実現するため、Gen5 NVMe SSD 4TB(読み込み速度10,000MB/s以上)を搭載しています。
これにより、大容量データの読み書きが高速に行え、解析処理の効率が上昇します。
さらに、Gen4 NVMe SSD 4TBを併設しており、作業領域と保存領域を分けて運用することで、データ管理の効率化と安定性を両立できます。このような分野で活躍されている方へ
- 地震解析
- 構造力学
- 計算物理
- 人工知能
- GPUコンピューティング
テガラのオーダーメイドPC製作サービスは、導入時の用途に加え、将来的な研究規模の拡大を見据えたシステムの拡張にも対応しています。
各種ソフトウェア要件に応じた構成のご提案はもちろん、研究環境全体の構築に関するご相談も承っています。
お客様のニーズに合わせて最適なソリューションをご提供しますので、どうぞお気軽にお問い合わせください。
通常24時間以内に担当者からご連絡いたします
主な仕様
CPU AMD Ryzen Threadripper PRO 9985WX 3.20GHz (boost 5.4GHz) 64C/128T メモリ 合計512GB DDR5 5600 REG ECC 64GB x 8 ストレージ1 4TB SSD M.2 NVMe Gen5 ストレージ2 4TB SSD M.2 NVMe Gen4 ビデオ NVIDIA RTX PRO6000 Max-Q 96GB ネットワーク on board (10GBase-T x2) 筐体+電源 ミドルタワー型筐体+1600W 80PLUS PLATINUM OS Alma Linux 保証 HDD返却不要サービス 1年 キーワード
・PyTorchとは
PyTorchは、Meta(旧Facebook)が開発したPythonベースのオープンソース振動学習フレームです。
動的計算グラフによる直感的な記述が特徴で、大学や企業の研究者に広く利用されています。
自然言語処理や医療画像解析など、多様な分野に対応し、GPUサポートや豊富なライブラリにより、高速かつ柔軟なモデル開発が可能です。・Tensorflowとは
TensorFlowは、Googleが開発したオープンソースの機械学習・深層学習ライブラリで、テンソル演算を通じた効率的な数値計算を可能にしています。
大学や企業の研究者、AIエンジニアなど幅広い技術者に利用されており、画像認識や自然言語処理など多様なタスクに対応。高い柔軟性とスケーラビリティを備え、研究から本番環境まで幅広い用途で活用されています。・OpenSWPCとは
OpenSWPCは、地震波の伝播を高精度に解析できるオープンソースの数値シミュレーションソフトです。
国内外の大学や研究機関、企業の防災・構造解析分野で広く活用されており、地震動や津波、地盤応答などの3次元解析に対応。
GPUによる高速演算やNetCDF・SAC形式の入出力をサポートし、再現性と拡張性の高い研究基盤として評価されています。・SPECFEMとは
SPECFEMは、スペクトル要素法(SEM)を用いた地震波動解析用のオープンソースソフトウェアです。
地球物理・地震学の研究機関やエネルギー関連企業で、震源解析や地盤特性評価などに活用されています。高い空間分解能と並列計算による大規模解析性能を備え、地球全体から都市スケールまでの精密なシミュレーションが可能です。・HBIとは
HBIは、地震サイクルを多次元で高精度に解析できる研究用シミュレーションソフトです。
境界要素法とH-マトリックスを活用し、2D・3Dの断層運動や摩擦、流体圧拡散など複雑な力学現象を再現可能。複雑な断層ジオメトリや摩擦モデルへの対応、並列処理による大規模解析が容易で、地震・地球物理分野の大学・企業研究者に広く利用されています。事例追加日:2025/10/22
- 事例No.PC-TUKJ253604
-

JAX機械学習・Abaqus解析向けワークステーション
用途:機械学習、JAX (Google-ML)、有限要素解析、Abaqus参考価格:1052700円お客さまからのご相談内容
Google-MLのJAX を活用した機械学習および数値シミュレーションを主用途に、汎用有限要素法ソフト (Abaqusなど) による解析も想定している。
予算は100万円程度。
Blackwell世代のGPUとIntel製CPU、GPUメモリは可能な限り大容量を希望。テガラからのご提案
GPUの選定について
JAXによる機械学習では、GPUのメモリ容量と演算性能が重要です。
Blackwell世代GPUは機械学習用途に適していますが、ご予算とのバランスを考慮し、RTX PRO 4500 (32GB VRAM) をご提案しています。
同じビデオメモリ容量で処理能力が高いGeForce RTX 5090も検討候補になりますが,電源や冷却性能の強化が必要となるため、ご予算内で最適な選択肢としてRTX PRO 4500を採用しました。CPU・メモリの選定について
有限要素解析ソフトAbaqusは、CPUのシングルスレッド性能が処理速度に直結します。
そこで、本構成では高いシングルスレッド性能を持つIntel Core Ultra 9 285Kを採用し、解析時間の短縮と安定性の両立を図りました。
メモリにはDDR5-6400を32GB×2枚 (計64GB) 搭載。将来的には空きスロットを活用し、最大128GBまで拡張可能です。電源容量と安定運用
高性能GPUとCPUの同時稼働に対応するため、電源には1000Wモデルを採用しました。
電力に余裕を持たせることで、ピーク時の負荷変動によるシャットダウンや性能低下を防ぎ、システムの安定性を確保しています。このような分野で活躍されている方へ
- 機械学習
- 構造解析
- 材料工学
- 計算力学
- 数値解析
テガラのオーダーメイドPC製作サービスは、導入時の用途に加え、将来的な研究規模の拡大を見据えたシステムの拡張にも対応しています。
各種ソフトウェア要件に応じた構成のご提案はもちろん、研究環境全体の構築に関するご相談も承っています。
お客様のニーズに合わせて最適なソリューションをご提供しますので、どうぞお気軽にお問い合わせください。
通常24時間以内に担当者からご連絡いたします
主な仕様
CPU Intel Core Ultra 9 285K 3.70GHz(8C/8T) + 3.20GHz(16C/16T) メモリ 合計64GB DDR5 6400 32GB x 2 ストレージ1 1TB SSD M.2 NVMe Gen4 ビデオ NVIDIA RTX PRO4500 32GB ネットワーク on board(2.5GBase-T x1) Wi-Fi,Bluetooth 筐体+電源 ミドルタワー型筐体+1000W 80PLUS PLATINUM OS Microsoft Windows 11 Professional 64bit キーワード
JAXとは
JAXは、Googleが開発したPython向けの数値計算ライブラリで、自動微分とJITコンパイルにより高速な並列処理が可能です。
主に機械学習や科学技術計算の分野で利用され、特に深層学習や大規模シミュレーションで効果を発揮します。NumPyコードをGPU/TPU対応で簡単に高速化でき、柔軟な関数変換機能 (vmap, scanなど) も特徴です。Google-MLとは
Google-MLは、Googleが提供する機械学習 (ML) 技術やツールの総称で、大規模データからパターンを学習し予測やコンテンツ生成を可能にするソフトウェア群です。
画像やテキスト、音声、動画など多様な形式のデータを用いて実験や高度な分析を行う際に広く使われています。オンプレミス環境からクラウドまで柔軟に利用可能であり、専門的な知識がなくても効率的にMLモデルを構築・運用できる点が評価されています。Abaqusとは
Abaqusは、ダッソー・システムズ社が提供する高度な有限要素解析 (FEA) ソフトウェアで、非線形解析やマルチフィジックス解析に強みを持ちます。
航空宇宙、自動車、防衛、家電など多様な産業の設計開発現場や大学の研究機関で幅広く使われており、複雑な物理現象のシミュレーションに適しています。ユーザーフレンドリーなGUIとスクリプトによる自動化機能を兼ね備え、細やかな材料モデルや複雑な解析ができる点が大きな特徴です。事例追加日:2025/9/24
- 事例No.PC-TRNJ253687
-
NeuroImaging・統計解析対応ワークステーション
用途:NeuroImaging解析、医用画像解析、Deep Learning推論、数値解析参考価格:977900円お客さまからのご相談内容
医用画像解析、特にNeuroImaging解析のためのマシンを検討している。
使用ソフトは下記の通り。【画像解析】
FreeSurfer、FSL、ANTs、Matlab、SPM、CONN (SPM/ Matlab環境)
【数値解析・統計処理】
R、Matlab、Python、Julia最近はCUDA対応が前提となっているツールが多く、Deep Learningによる推論やテスト的な学習にも活用する予定。そのため、VRAMが16GB以上のGPUを希望。
筐体については、Define 7 (幅240x高さ475x奥行547(mm)) は大きすぎるため、ATX対応筐体、具体的には Define 7 Compact (幅210x高さ474x奥行427(mm) ) 程度のサイズを想定している。
また、マザーボードはASRock製とRyzen 9000系の相性問題が気になっており、選定時はBIOSの最新版を適用、またはMSIなど他メーカー製の採用を検討したい。
マザーボードの条件は、・電源フェーズ:14+2+1以上 (CPU向けに14フェーズ以上)
・SATAポート:4ポート以上加えて、HDD返却不要サービスもオプションで利用したい。
※HDD返却不要サービスの詳細はこちらテガラからのご提案
NeuroImaging (神経画像解析) ツールを軸に、統計解析・信号処理、Deep Learningの試験的導入にも活用できるよう、多用途に適した構成をご提案しました。
GPU構成と解析用途への対応
CUDA対応の画像解析ツールや、軽量な学習処理への活用に備え、GPU には VRAM 16GB 搭載の NVIDIA GeForce RTX 5080 を選定しました。
主要な研究向けフレームワークの要件に対応しており、今後の用途拡張にも柔軟に適応できる構成です。安全性を考慮した筐体選定
小型筐体をご希望いただいていましたが、干渉や発熱の懸念があるため採用を見合わせています。
近年のGPUは横方向に補助電源端子を備える構造が一般的で、コンパクト筐体ではパネルとの隙間が狭いため、ケーブルの取り回しに無理が生じやすくなります。
その結果、コネクタ部に過剰なテンションがかかり、発熱や焼損といった重大なトラブルにつながるケースが国内外で報告されています。こうしたリスクを回避し、安全かつ長時間の連続稼働に耐えられる環境を確保するため、ゆとりのある内部スペース備えたFractal Design Define 7 ミドルタワー筐体をご提案しました。
マザーボードの選定について
マザーボードには、お客様のご要望を踏まえ、ASUS TUF GAMING X870E-PLUS WIFI7を選定しました。
このモデルは、電源フェーズを16+2+1 (CPU向け16フェーズ) 、S-ATA 6Gポートを4基搭載しており、連続稼働時でも電圧のブレが抑えられ、処理中のトラブルを回避しやすい設計です。
なお、ASRock X870 Steel Legend WiFiについても、弊社での故障報告はこれまでに確認されておらず、安定した動作実績があります。
弊社では、すべてのPCに対して出荷前の高負荷テストを実施しています。ASRock製を採用する場合も、BIOSの更新など必要な設定を行った上で提供しております。
ご希望に応じて仕様の調整も行えますので、安心してご選択いただけます。このような分野で活躍されている方へ
- 医用画像解析
- 神経科学
- 臨床研究
- 医用工学
- 計算神経科学
ご利用予定のツールやご使用環境に応じたカスタマイズも承っております。まずはお気軽にお問い合わせください。








通常24時間以内に担当者からご連絡いたします
主な仕様
CPU AMD Ryzen 9 9950X 4.30GHz (Boost時最大5.70GHz) 16C/32T メモリ 合計128GB DDR5 5600 32GB x 4 ストレージ1 4TB SSD M.2 NVMe Gen4 ストレージ2 20TB HDD S-ATA ビデオ NVIDIA GeForce RTX5080 16GB ネットワーク on board(2.5G x 1) Wi-Fi x 1 筐体+電源 ミドルタワー型筐体 1000W 80PLUS PLATINUM OS OSなし 保証 HDD返却不要サービス 1年 キーワード
・NeuroImaging解析 (神経画像解析) とは
NeuroImaging解析は、医学・心理学・情報科学などの研究者によって、脳疾患の診断や精神活動の可視化のために利用される解析方法です。
特に、脳機能の異常や発症前の変化の検出、機械学習を用いた疾患特徴抽出を目的に使用されています。・FSL (FMRIB Software Library) とは
FSLは、主に化学・生命科学分野の研究者が、分子やタンパク質の超高速反応機構の解明を目的に使用するツールセットです。
反応遷移状態や構造ダイナミクスをリアルタイムに観測し、生命現象や物質変化の詳細を調査するために活用されています。・Rとは
主に医学・バイオインフォマティクス、社会科学、工学など、広い分野の研究者が使用するオープンソースの統計解析ソフトです。
データ解析や統計モデル構築のほかに結果の視覚的な表示に使用され、様々な用途で広く利用されています。事例追加日:2025/8/21
- 事例No.PC-11829
-
RTX6000Ada搭載 AI開発用マシン
用途:RTX6000 Adaを用いたAIモデルの活用参考価格:2273700円この構成はAIモデルやニューラルネットワークの学習・実行にフォーカスしています。
搭載されているハイエンドGPU「RTX6000 Ada」は、DeepLearningなどの高度な計算タスクに特化したGPUで、48GBのビデオメモリを実装しています。主要なAIモデルで大きなバッチサイズを利用する際、大容量のビデオメモリは有利に働きます。参考記事:「主要なAIモデルにおける RTX シリーズ GPUのパフォーマンス比較検証」 TEGSYSでは、先行する事例としてRTX A6000 Adaを2台搭載した『事例No.PC-11248 RTX6000Ada x2枚搭載 AI開発用マシン』が高い評価を得ており、多数のお問い合わせやご注文・頂戴しています。
本事例はPC-11248をベースにしつつ、”コストに配慮したGPUマシン”のコンセプトのもとRTX A6000 Ada x1台構成でGPU以外のスペックも全体的に見直しを行い、より導入しやすいコスト・構成を目指しました。なお、本事例の構成はPCIeスロットを複数備えているので、将来的なGPUの増設に対応しています。
※GPU増設のご予定がある場合は、別途仕様を変更してご案内しますのでお知らせください。また、CPUにはIntel Xeonシリーズを採用しているので、AIモデル開発以外の用途でも十分な処理能力を発揮できます。
その他、大容量メモリ搭載やCPUコア数、ストレージ容量変更など、ご要望に合わせたカスタムをご提案を承っております。
どうぞ、お気軽にご相談ください。


通常24時間以内に担当者からご連絡いたします
主な仕様
CPU Intel Xeon W3-2435 (3.10GHz / 8コア) メモリ 64GB REG ECC ストレージ1 1TB SSD M.2 NVMe Gen4 ストレージ2 4TB HDD S-ATA ビデオ NVIDIA RTX6000 Ada 48GB ネットワーク on board (2.5GbE x1, 10GbE x1) 筐体+電源 タワー型筐体 + 1000W OS Microsoft Windows 11 Professional 64bit その他 CUDA Toolkit 12インストール 事例追加日:2024/02/21
- 事例No.PC-11180
-

RTX6000 Adax4枚搭載マシン
用途:GPGPUを用いたDeepLearning参考価格:12103300円お客さまからのご相談内容
深層学習用マシンの導入を検討している。予算1300万円以内で、適切な構成を提案してほしい。
GPUのVRAM容量を重視しており、それと同時に適切な納期 (入手に時間がかかりすぎない) ことも条件としたい。
具体的なスペックは、CPUはIntel Xeon Platinum 8368 (2.40 GHz 38コア) x2相当で、メモリ容量は512GB以上がよい。
GPUの候補はNVIDIA A100、 NVIDIA V100、 NVIDIA RTX6000 Ada、 NVIDIA A6000 の4つ。この中のどれかを総VRAM容量が128GB程度になるように搭載したいので、納期・コスト・合計VRAM容量の観点から最適なものを選定してほしい。
ストレージは20TB程度、OSはRed Hat Enterprise Linux 8を希望する。テガラからのご提案
ご要望を踏まえて、ベストな構成をご提案しました。
CPUは第3世代Xeon Platinumをご希望いただきましたが、2024年1月現在、後継品である第4世代の製品が展開されています。
そのため、第4世代XeonでIntel Xeon Platinum 8368と同等スペックのIntel Xeon Platinum 8460Y+ (2.00GHz 40コア) x2を選択しています。DeepLearningに適したGPUの選定
GPU候補のうち、NVIDIA A100はご相談をいただいた時点で納期が長期化しており、納期を重視する場合にはマッチしない製品でした。
V100はA100と同じGPGPU専用カードの旧世代製品ですが、V100は既に終息しており、仮に入手できたとしてもDeepLearning用途で利用される単精度・半精度の演算性能はアーキテクチャーの世代差によりRTX A6000やRTX6000 Adaよりも低くなります。
また、現時点で総合的には最高の性能を持ったGPUにNVIDIA H100がありますが、非常に高額でありコストパフォーマンスの観点からも扱いの難しい製品です。
これらのことより、総VRAM容量128GB程度の組み合わせを効率よく実現する場合A6000、 もしくはRTX6000 Adaをおすすめします。本件のお客様へのご提案では、ご予算に合わせて、RTX6000 Ada x4枚(総VRAM容量192GB)を選択しています。
また、本構成はRTX6000 Adaを合計9枚まで増設可能です。
なお、実際の運用においては消費電力の都合上、200V環境が必要となります。本事例の構成は、お客様から頂戴した条件を元に検討した内容です。
いただいた条件に合わせて柔軟にマシンをご提案いたしますので、掲載内容とは異なる条件でご検討の場合でも、お気軽にご相談ください。


通常24時間以内に担当者からご連絡いたします
主な仕様
CPU Intel Xeon Platinum 8460Y + (2.00GHz 40コア) x2 メモリ 512GB REG ECC (64GB x8) ストレージ 7.68TB SSD S-ATA ×4 (RAID5) ビデオ on board GPU NVIDIA RTX 6000 Ada 48GB ×4 ネットワーク on board (10GBase-T x2) 筐体+電源 4Uラックマウント筐体 + リダンダント電源5400W OS Rocky Linux 8 キーワード
・DeepLearningとは
DeepLearningは機械学習の一種であり、多層のニューラルネットワークを用いて高度なパターン認識や予測を行う手法。一般的に大量のデータを必要とするため、データが豊富な場合に効果的な手法とされている。 また、DeepLeanigは画像認識や音声認識、自然言語処理などの分野で広く用いられている。複雑な特徴や関係性を学習することができるため、従来の機械学習手法よりも高い精度を発揮することができる。事例追加日:2024/01/12
- 事例No.PC-11641C
-
AIモデル開発 入門向けマシン [スタンダードモデル]
用途:DeepLearning入門用途かつ将来のGPU増設に対応した構成参考価格:992200円このモデルは入門用かつ将来的な増設に対応した構成となります。
エントリーモデルと同様にディープラーニングに使われる基本ソフトも設定されています。
エントリーモデルとの大きな違いは、GPUの搭載枚数。エントリーモデルはGPUは1枚までの対応となりますが、このモデルは後からGPUを追加で1枚増設することが可能です。
また、CPUにはXeonを利用してるためディープラーニング用途以外にも併用して利用されたい場合の選択肢になります。
具体的には、このモデルをベースにカスタムすることで、大容量のメモリや16コアを超える構成などを実現できます。通常24時間以内に担当者からご連絡いたします
主な仕様
CPU Xeon W3-2435 (3.10GHz 8コア) メモリ 64GB REG ECC ストレージ 2TB SSD S-ATA ビデオ NVIDIA Geforce RTX4090 24GB ネットワーク on board (2.5GbE x1 /10GbE x1) 筐体+電源 タワー型筐体 + 1500W OS Ubuntu 22.04 その他 CUDA Toolkit 11.8インストール
Tensorflow/PyToch/Docker(もしくはSingularity)事例追加日:2024/01/09
ご注文の流れ
 |
お問い合わせフォームよりご相談内容をお書き添えの上、 お問い合わせください。 (お電話でもご相談を承っております) |
 |
弊社より24時間以内にメールにてご連絡します。 |
 |
必要に応じてメールにて打ち合わせさせていただいた上で、 メール添付にてお見積書をお送りします。 |
 |
お見積もり内容にご納得いただけましたら、メールにてご注文ください。 ご注文確定後、必要な部材を手配し PCを組み立てます。 (掛売りの場合、最初に新規取引票のご記入をお願いしております) |
 |
動作チェックなどを行い、納期が確定いたしましたらご連絡いたします。 (納期は仕様や製造ラインの状況により異なります) |
 |
お客様のお手元にお届けいたします (ヤマト運輸/西濃運輸) |
お支払い方法
お支払い方法は、お見積もりメール・お見積書でもご案内しています。
| 法人掛売りのお客様 |
| 原則として、月末締、翌月末日払いの後払いとなります。 |
| 学校、公共機関、独立行政法人のお客様 |
| 納入と同時に書類三点セット(見積書、納品書、請求書)をお送りしますのでご請求金額を弊社銀行口座へ期日までにお振込み願います。 先に書面での正式見積書(社印、代表者印付)が必要な場合はお知らせください。 |
| 企業のお客様 |
| 納品時に、代表者印つきの正式書類(納品書、請求書)を添付いたします。 ご検収後、請求金額を弊社銀行口座へお支払い期日までにお振込み願います。 |
| 銀行振込(先振込み)のお客様 |
| ご注文のご連絡をいただいた後、お振込みを確認した時点で注文の確定とさせていただきます。 |
修理のご依頼・サポートについて
弊社製PCの保証内容は、お見積もりメールでもご案内しています。
■お問合せ先
テガラの取り扱い製品に関する総合サポート受付のWEBサイトをご用意しております。
テガラ株式会社 サポートサイト
※お問い合わせの際には、「ご購入前」と「ご購入後」で受付フォームが分かれておりますので、ご注意ください。
| メール | support@tegara.com |
| 電話 | 053-543-6688 |
■テグシスのサポートについて
保証期間内の修理について
保証期間内におけるハードウェアの故障や不具合につきましては、無償で修理いたします。
ただし、お客様による破損や、ソフトウェアに起因するトラブルなど保証規定にて定める項目に該当する場合は保証対象外となります。
保証期間経過後も、PCをお預かりしての初期診断は無料で実施しております。
無料メール相談
PCの運用やトラブルにつきまして、メールでのご相談を承ります。経験・知識の豊富な技術コンサルタントが無料でアドバイスいたします。
※調査や検証が必要な場合はお答えできなかったり、有償対応となることがあります
オプション保証サービス
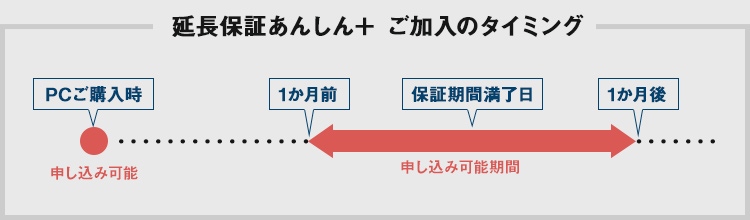
| 「あんしん+」 もしもの時の延長保証サービス |
|
PCのご購入時にトータル5年までの延長保証をご選択いただけます。また、ご購入後にも延長保証を申し込むことができます。
|
| HDD返却不要サービス |
|
保証期間内にPCのHDD(SSD)が故障した場合、通常、新品のHDDとの交換対応となり、故障したHDDはご返却いたしません。 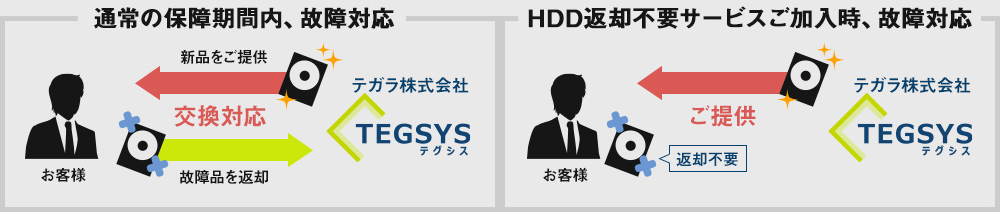
|

| オンサイト保守サポート | |
|
故障発生時、必要に応じエンジニアスタッフが現地へ訪問し、保守対応を行うサービスです。
|
「お客様だけのオーダーメイドPC」を製作しています。
用途に応じた細かなアドバイスや迅速な対応がテガラの強みです。
上記の仕様はテガラでお客様に提案したPC構成の一例です。
掲載内容は提案当時のものであり、また使用する部材の供給状況によっては、現在では提供がむずかしいものや、部材を変更してのご提案となる場合がございます。
参考価格については、提案当時の価格(送料込・税込)になります。
ご相談時期によっては価格が異なる場合がございますので、あらかじめご了承ください。



