- 事例No.PC-11242
-
この事例は掲載から時間が経過しているため内容が古い可能性があります。
用途や特徴・要件をふまえた、最新構成でのご提案をご希望の場合は、お気軽にお問い合わせください。 参考価格:
参考価格:
2,528,900円事例追加日:2023/11/09生物学向け大規模言語モデルの学習用マシン
用途:生物学向け大規模言語モデル (ProteinBERT、 ChemBERTa、 HyenaDNAなど) の学習お客さまからのご相談内容
生物学向け大規模言語モデルの学習用マシンの導入を検討している。
ProteinBERT、 ChemBERTa、 HyenaDNAといった生物学で用いられる大規模言語モデルを事前学習から実行したいと考えている。ProteinBERTはNvidia Quadro RTX 5000、ChemBERTaはNVIDIA Tesla T4、HyenaDNAはNVIDIA A1…
テガラからのご提案
お客さまご希望の条件に沿った構成をご提案しました。
ご予算・利用環境を踏まえたうえで、GPU性能を重視した構成です。GPUの選定について
GPUはNVIDIA RTX A6000 x2枚を搭載しています。
ProteinBERT開発元の公式サイトによると、学習済みモデルの構築にはNVIDIA RTX5000を用いて1か月ほど要したと記…主な仕様
CPU Intel Xeon W5-2455X (3.20GHz 12コア) メモリ 128GB REG ECC ストレージ1 2TB SSD M.2 ストレージ2 4TB SSD S-ATA ビデオ NVIDIA RTX A6000 48GB x2 ネットワーク on board (1GbE x1 /10GbE x1) 筐体+電源 ミドルタワー型筐体 + 1500W OS Microsoft Windows 11 Professional 64bit
- 事例No.PC-10873
-
この事例は掲載から時間が経過しているため内容が古い可能性があります。
用途や特徴・要件をふまえた、最新構成でのご提案をご希望の場合は、お気軽にお問い合わせください。 参考価格:
参考価格:
1,466,300円事例追加日:2023/04/13自然言語処理モデル用ワークステーション
用途:BERTのFine-tuningおよびNVIDIA Clara Parabricksお客さまからのご相談内容
手持ちのGPU x2台 (RTX A6000 2台またはA100 2台)を使用するためのマシンを購入したい。
希望する条件は以下の通り。・100Vの電源環境で動作する構成を希望
・消費電力はできるだけ小さくしたい
・居室で使用するため、GPU使用時以外は静音が望ましい。ただし、GPU使用時の稼働音は許容する
テガラからのご提案
ご要望に合わせて構成を検討しました。
消費電力を意識して、Ryzen Threadripper構成としています。搭載するGPUはRTX A6000を想定しています。
A100はGPU本体に冷却FANがないため、GPU冷却機構を持つGPGPUサーバー用の筐体が必須となり、ご予算内での実現は難しいとお考えください。100V環境で利用できる…
主な仕様
CPU AMD Ryzen ThreadripperPRO 5975WX (3.60GHz 32コア) メモリ 256GB REG ECC ストレージ 1TB SSD M.2 ビデオ on board (VGAx1) ネットワーク on board (1GbE x1 10GBase-T x1) 筐体+電源 タワー型筐体 + 1600W OS Ubuntu 20.04 ご注文の流れ

お問い合わせフォームよりご相談内容をお書き添えの上、 お問い合わせください。
(お電話でもご相談を承っております)
弊社より24時間以内にメールにてご連絡します。 
必要に応じてメールにて打ち合わせさせていただいた上で、 メール添付にてお見積書をお送りします。 
お見積もり内容にご納得いただけましたら、メールにてご注文ください。
ご注文確定後、必要な部材を手配し PCを組み立てます。
(掛売りの場合、最初に新規取引票のご記入をお願いしております)
動作チェックなどを行い、納期が確定いたしましたらご連絡いたします。
(納期は仕様や製造ラインの状況により異なります)
お客様のお手元にお届けいたします (ヤマト運輸/西濃運輸) お支払い方法
お支払い方法は、お見積もりメール・お見積書でもご案内しています。
法人掛売りのお客様 原則として、月末締、翌月末日払いの後払いとなります。 学校、公共機関、独立行政法人のお客様 納入と同時に書類三点セット(見積書、納品書、請求書)をお送りしますのでご請求金額を弊社銀行口座へ期日までにお振込み願います。
先に書面での正式見積書(社印、代表者印付)が必要な場合はお知らせください。企業のお客様 納品時に、代表者印つきの正式書類(納品書、請求書)を添付いたします。
ご検収後、請求金額を弊社銀行口座へお支払い期日までにお振込み願います。銀行振込(先振込み)のお客様 ご注文のご連絡をいただいた後、お振込みを確認した時点で注文の確定とさせていただきます。 修理のご依頼・サポートについて
弊社製PCの保証内容は、お見積もりメールでもご案内しています。
■お問合せ先
テガラの取り扱い製品に関する総合サポート受付のWEBサイトをご用意しております。
テガラ株式会社 サポートサイト※お問い合わせの際には、「ご購入前」と「ご購入後」で受付フォームが分かれておりますので、ご注意ください。
メール support@tegara.com 電話 053-543-6688 ■テグシスのサポートについて
保証期間内の修理について保証期間内におけるハードウェアの故障や不具合につきましては、無償で修理いたします。
ただし、お客様による破損や、ソフトウェアに起因するトラブルなど保証規定にて定める項目に該当する場合は保証対象外となります。
保証期間経過後も、PCをお預かりしての初期診断は無料で実施しております。無料メール相談
PCの運用やトラブルにつきまして、メールでのご相談を承ります。経験・知識の豊富な技術コンサルタントが無料でアドバイスいたします。
※調査や検証が必要な場合はお答えできなかったり、有償対応となることがありますオプション保証サービス
「あんしん+」 もしもの時の延長保証サービス PCのご購入時にトータル5年までの延長保証をご選択いただけます。また、ご購入後にも延長保証を申し込むことができます。
延長を申し込みいただきますと、標準保証と同等の保証を期間満了まで受けることができます。
なお、PCの仕様によっては料金が異なる場合があります。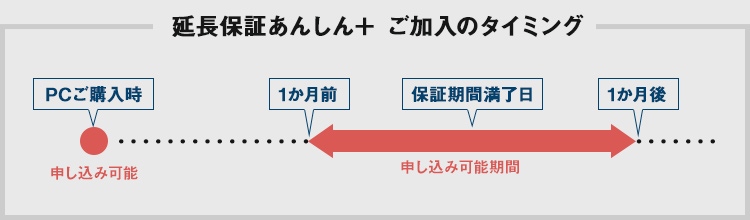
※仕様によっては保証期間の延長ができない場合があります。
HDD返却不要サービス 保証期間内にPCのHDD(SSD)が故障した場合、通常、新品のHDDとの交換対応となり、故障したHDDはご返却いたしません。
しかしこの「HDD返却不要サービス」にご加入いただければ、保証期間内にHDD(SSD)が故障した場合には新品のHDDをご提供いたしますが、故障したHDDを引き渡していただく必要はありません。お客さまの大切なデータの入ったHDDをお手元に保管しておくことができます。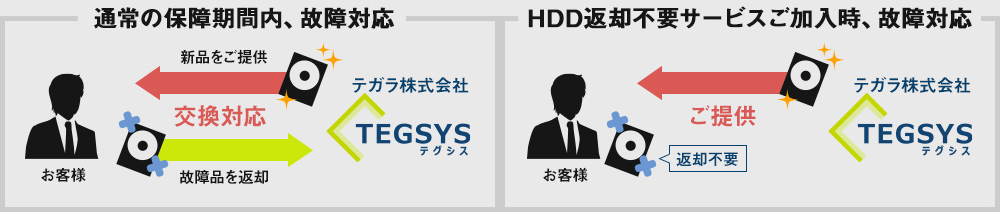

オンサイト保守サポート 故障発生時、必要に応じエンジニアスタッフが現地へ訪問し、保守対応を行うサービスです。
発送にかかる手間、時間を短縮できますので、緊急性の高い保守に最適です。費用ご参考(目安)
本体+延長保証代金の10%~
※ 製品の性質や価格帯、条件等により異なります。
★TEGSYS オンサイト保守利用規約はこちら (pdf)お客様のご要望をうかがい、最適なPCの構成をご提案する
「お客様だけのオーダーメイドPC」を製作しています。
用途に応じた細かなアドバイスや迅速な対応がテガラの強みです。上記の仕様はテガラでお客様に提案したPC構成の一例です。
掲載内容は提案当時のものであり、また使用する部材の供給状況によっては、現在では提供がむずかしいものや、部材を変更してのご提案となる場合がございます。参考価格については、提案当時の価格(送料込・税込)になります。
ご相談時期によっては価格が異なる場合がございますので、あらかじめご了承ください。
関連サイト

- テガラ株式会社のコーポレートサイトです。

- 研究開発者向け海外製品調達・コンサルテーションサービス「ユニポス」
専門的なソフトウェアや、日本未発売の最新ハードウェアなど研究開発に必要な製品を世界中から調達し、ご提供します。

- 『ターン・キー』で使える研究開発・実験用機材一式構築サービス「TKS事業部」
テガラの主要サービス「UNIPOS」「TEGSYS」「サポート」および「コンサルテーション」をベースに、それぞれの研究開発テーマに特化したターンキーシステムを提供するサービスです。

- 研究開発者向け情報発信メディア「テガカリ」
最新の海外製品のリリース情報や研究開発向けコンピュータ事例紹介、技術情報記事などをお届けしています。